基于bootstrap前端框架和struts2,spring以及hibernate后端框架的学生信息管理系统的设计与开发

基于bootstrap前端框架和struts2,spring以及hibernate后端框架的学生信息管理系统的设计与开发
|
|
摘 要
Struts2,Hibernate,Spring框架是JavaEE应用中比较主流的开发框架。本论文的学生信息管理系统前端MVC由Struts2开发,持久化层和数据库的处理是通过Hibernate来开发,然后使用Spring整合Struts2和Hibernate,整合系统不同层次,形成一个完整的系统。
本文研究了Spring的面向切面和依赖注入的核心概念,对其进行了深入探讨,并且探究了Hibernate的ORM的概念和基本原理,并探讨了Struts2的拦截器机制。在此基础之上,以LinzhiOS的系统开发过程,具体说明这几个框架在实际中的运用。
本文详细说明实现LinzhiOS系统从背景介绍到基于Strtus2,Hibernate,Spring框架开发完成的过程。论文首先阐述了LinzhiOS系统的体系架构设计,然后在关于Struts的章节,阐述了MVC的设计思想;论文还详细讲述了Hibernate对数据库的操作过程和实现对象与数据表的映射过程;在关于Spring的章节中,详细分析了Spring的代理模式和工厂模式,这些是Spring的原理性东西。
论文的前面部分主要是纵向的实现LinzhiOS系统的主要功能,论文的最后两章,主要是从安全和性能的角度对系统从横向的角度切入,对系统进行了分析和讲解,并且在安全和性能方面的评估。
关键字:Struts2;Hibernate;Spring;LinzhiOS
Abstract
Struts2, Hibernate and Spring are the mainframeworks which apply to JavaEE development. This paper develop base onStruts2 for front-page’s MVC modal, and using hibernate to develop persistentObject and Database, build the system a whole with the technology Springframework.
Spring’s AOP and Dependency Inject will bestudied in this paper, we will talk about the conception of ORM about Hibernateas well, the same time, and the interceptor is also our theme in the chapterabout Struts2. Base on those technology then we build the LinzhiOS system,which is specific talk about the application about those technologies.
We will specifically instruct the LinzhiOSfrom background to finishing the system with Struts2, Hibernate and Spring. Inthe begin, we will talk about the framework design about LinzhiOS system, theMVC modal and the deeper thought about MVC will be followed in the Chapterabout Struts2. We will detailed make it clear about the database design anddeal with hibernate configuration files which are not that easy when it comesabout Hibernate. In the chapter about Spring, we will focus on proxy patternand factory pattern which is base about Spring.
Compare with the accomplishment about thesystem in front, the last part mainly focus on something like security andperformance. In this session, we think about the system with a different view,and try to analyses the system’s security and performance, and test them inthose aspect.
Keywords:Struts2;Hibernate;Spring;LinzhiOS
第一章 绪 论
1.1背景
现在正在使用的学生信息管理系统有些不好的缺点,针对这些不好的地方进行的优化和做性能提升。具体有以下几个方面是很有提升空间和值得改进的:
1.前端界面的用户友好性很不足。
2.很多事物逻辑操作繁琐。对于一次简单选课,需要多次单击鼠标进行选择,逻辑判断,这个在易用性上很打折扣。同样的道理,查成绩也需要多次单击按钮,多次进行删选。这些都是系统不合理的地方,需要改进。
3.在系统繁忙的情况下,用5秒防刷这种方式来减小负载是很不负责任而且很粗暴的做法,也需要改进。
上述的系统所存在的这些不足,是做这个系统的出发点。希望能够开发一个在易用性,用户友好性,用户体验等方面都有较好改进和完善的学生信息系统。
现在正在使用的系统是上世纪90年代到本世纪初期在设计完成并大范围投入使用的系统。当时的软件行业的大环境更多是在乎功能性。功能性有没有问题,性能有没有满足要求,这些是当时的主要考量标准,至于易用性和用户体验等概念是在近几年才开始成为收到关注的问题。随着新技术的发展,也才使得易用性和用户体验问题有了解决和实现的可能。这正是这个系统视图是尝试的东西。本设计的一个初衷便是通过这几年流行的一些主流的技术(例如jQuery,JavaScript等)在易用性和用户体验上做出一些改进。这也正是这个系统的目的所在。
本系统在原系统的布局,页面呈现,逻辑处理等各个方面都会有很大的不同。完全独立于原系统的重新设计和实现。
1.2此课题的课程设计的目的
以此作为课题的课程设计的目的有以下三点:
希望从前端到后台设计并实现一个完整的,成熟的基于现代技术的系统。大学本科的四年时间里,曾经做过几次大的课程设计,例如,大二下学期的操作系统的课程设计,大三上学期的软将工程和数据库的课程设计等等,其中,每次的课程设计只是更多的针对相关课程进行的设计和实现功能,在其他方面考虑的比较少,比如说,在设计操作系统的进程调度时,我的实现呈现结果的方式是通过CMD的命令行形式的模拟调度,在软件工程和数据库的实验设计中,虽然设计了web的前端,但是前端的实现比较简陋。大量基于简单的HTML和CSS,以及少量的JavaScript……当时,由于时间比较短,大概每次课程设计都只有一到两周。所以没有对新技术进行深入的学习和了解。对于这些技术不是不好,只是觉得与现在行业中比较热门并且成熟的技术总有一定的距离,而相比这次毕业设计,在时间上能够更充裕,有更多的时间去准备响应的技术,因此也希望在设计中运用更成熟的技术,以及更多的考虑更好的解决方式。本次毕业设计的技术上希望挑战目前业内普遍认可并且主流的设计思路和设计语言以及实现思路:前端,运用第三方前端库bootstrap完成前端的基本页面的设计和具体的呈现效果(View),运用JavaScript和jQuery实现前端的动态操作和事件响应;后台主要通过Struts2,Hibernate,Spring框架设计并实现服务器端与数据库实现。
选择本题目作为毕业设计的方向目的之二,通过毕业设计的实践练习,使自己的能力得到提升。通过在实践中提升自己对知识的掌握程度。训练自己的专业素质,提高自己的技术水平。另外也想通过这次毕业设计挑战一下自己的能力。因为设计题目下对应的技术和知识量以及工作量都不可小觑,而且所应用到的技术对于我来说尚且比较生疏,所以对我来说是一个挑战。
目的之三,如果本系统能有较好的表现效果,稳定的表现,及不错的性能,则可以为使用该系统的终端用户提供优于原来系统的服务,提供更友好的用户界面,更丰富和质感的交互效果,更易于操纵和使用。这也正是本系统的价值和意义所在。
1.3完成本系统设计的预期目标
希望系统最终的完成后,相对于现有的系统来说,能做到在用户友好性,操作易用性,用户页面呈现,用户事件响应方面有一定的作用。具体来说:希望呈现在终端用户面前的界面友好,操作简单便捷,功能完善,并且表现稳定的系统。具体表现为:
1.能够提供给终端用户(学生)通过网络选课,查询成绩等功能,能够为用户提供简洁但不失美感的呈现页面,能提供用户多终端多平台(HTML5页面,提供PC浏览器端,移动设备的浏览器等)兼容的一致性的用户体验。
2.提供合理的UI交互的动画效果,提供正确实时的响应用户请求,对用户操作给你正确及时的响应(主要针对选课)。
3.服务器端,对用户请求,对于符合其权限范围之内,予以正确实时的响应,并友好的呈现在用户面前。
第二章 系统的体系结构
2.1系统的体系结构
本文中实现的基于Struts2,Hibernate和Spring框架的学生信息管理系统(以下简称LinzhiOS),在体系架构上使用的是贫血模式的设计架构。贫血模式的体系结构即是说javaBean 中只包含相应的属性和相对应的get方法和set方法,而不包括其他的与之相关的业务逻辑方法,将对应的业务逻辑方法放在业务逻辑组件中,这种架构设计的优点是简单,直观,快速开发,也是很多web开发中所主要使用的一种体系架构。
相对于这种架构的还有其他体系结构方法。例如,领域对象模型,根据面向对象的规则设定,每个Java类都应该提供其相关的业务方法。此时我们设计的Java类就是完备的DO(DomainObject,即领域对象),数据的载体的同时,也包含了响应的业务逻辑方法。它也有所不足的地方,比如,我们需要考虑的一个问题是:哪个业务逻辑方法应该放在Domain Object对象中实现?当DO中有很多逻辑方法的时候,这种缺点尤为明显。另外哪些业务逻辑方法完全由业务逻辑对象实现呢?这是个很大的问题,也会有很模糊并且都可行的设计方法。但是会显得凌乱:例如有些逻辑方法放在A类里面也可以,放在B类里面也可以。
本系统采用贫血模式的体系结构。DO类只存相应的数据,还有对应的getXXX()方法和setXXX()方法,除此之外什么也没有,而对应的与业务逻辑相关的方法放在了Service层对应的相应的组件中。每个组件集成相应的功能,具体实现在DAO层的Impl中和Service层的Impl中。
使用四层架构的系统设计层次,每一层分别是:表述层,服务层,持久化层,数据库层。在每一层中,下层为上层提供接口,上层调用下一层的接口提供的服务,对其他层透明。下层为上层提供接口,这是面向接口编程。面向接口编程的一个优点从这里也能看出,只需要关心提供的服务的接口,而不必考虑具体的接口所提供的服务的方法。四层架构是从三层架构发展而来的,ORM的设计思想将数据库操作内化为程序应用的面向对象层的操作,然后通过面向对象的方法操作数据库,对于底层的数据库则完全不用管是MySQL还是Oracle,持久层的操作屏蔽了底层的数据操作,而且支持跨数据库操作。本系统采用四层体系架构。对于这种结构栈的层次架构的层与层的关系有点像TCP/IP的协议栈那样,下层为上层提供接口,下层的实现对上层是透明的。具体体系结构参见图2.1。
2.2开发工具
本系统将会用到的开发工具主要包括但不限于:
|
另外,本论文的设计书写顺序并未像软件工程中的瀑布模型那样进行,而是按照上述途中的体系结构那样从Struts2层的设计实现,然后完成Service的设计实现,进而完成DAO层持久层 设计实现过程,最后整合Spring框架的过程,最终完成整个系统的实现。其中以Struts2,Hibernate,Spring每个框架的植入过程为章节进行详解。
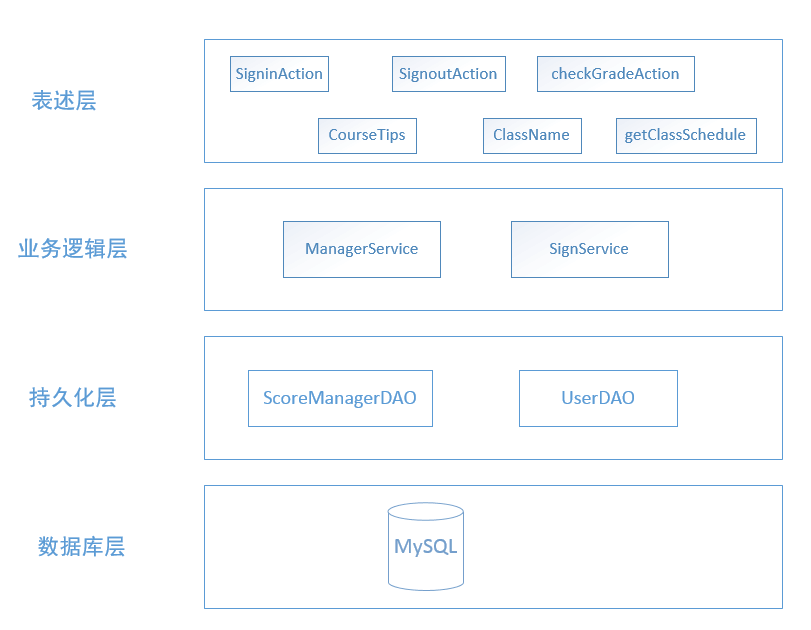
图2.1 四层结构
第三章 基于Struts2的前端设计与实现
3.1 Struts2 的发展历史和背景
Struts2 由两个经典的MVC框架——WebWork和Struts1——发展起来,结合了webwork和Struts1的优点,并且克服了两者的不足。[2]所以Struts2 设计上耳目一新,而且在实际项目中作为一个非常优秀的MVC框架体现在它的易用性上面。Struts2允许使用普通的,一般的普通的Java对象可以作为作为Action,而这在Struts1中是不被允许的;另外Action的execute()方法也不再与Servlet API耦合,因而更易于测试;支持更多的视图技术;基于AOP思想的拦截器机制,提供了极好的可扩展性;更强大更易用的输入校验功能;整合的Ajax支持等,这些都是Struts2的巨大吸引力。
3.2 MVC思想的概述
随着应用系统的逐渐增大系统的业务逻辑复杂度将以几何级数的方式增长。按照功能将应用中的各组件进行分类,这就是MVC最本质的思想。不同的技术运用在不同的组件上,并且强烈建议使用明确而且严格的分层思想,为了提供优良的封装,将不同的组件限制在不同的层次中,使得各层次之间解耦合,通过松耦合的方式组织在一起。
3.2.1 Struts2的发展
Java Web应用的结构经历了Model1 和Model2 两个时代。
Model2已经是基于MVC架构模式的设计模式。Struts2的架构中,前端的Controller是由Servlet来担当的,Serlvet把用户的request,通过逻辑控制,把用户的请求传递给后端的JavaBean,由JavaBean来完成实际的业务逻辑的相关事务。最后,转发到响应的JSP页面处理显示逻辑处理之后的结果。其具体的实现方法参见图3.1。
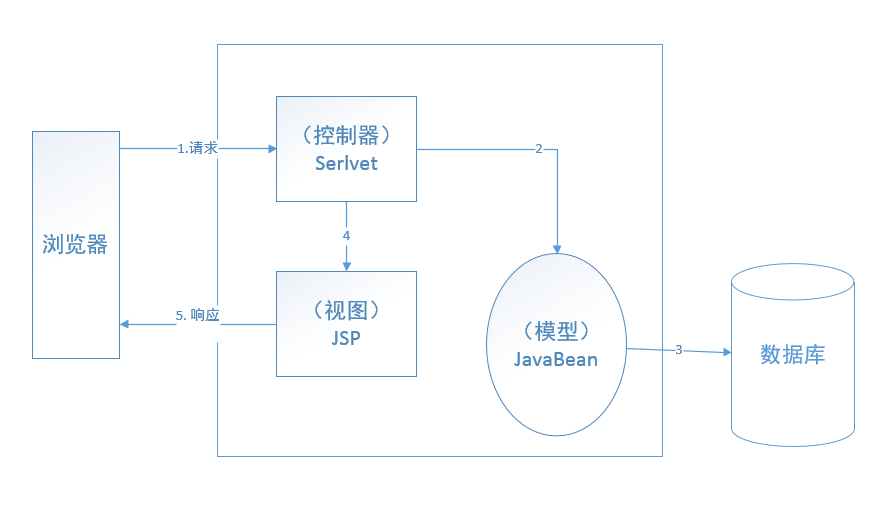
图3.1 Model2 的流程
在Model2 下JSP履行表现层角色的任务,主要职务是将需要呈现给用户的结果呈现给终端用户的浏览器客户端上,用户在浏览器中的JSP页面上的请求(Request)全部提交交给Servlet,统一由Servlet负责将请求通过简单的控制逻辑转发给相应的 JavaBean,进而由JavaBean来完成实际的业务逻辑的相关事务,完成业务逻辑。最后,转发到响应的JSP页面处理显示结果。在Model2 模式下,javaBean是模型(Model),JSP页面作为视图(View),Serlet是控制器(Controller)。[8]
MVC模式的引入导致了Model2变得组件化。另一方面由于对高集成度的系统的开发相适应的是相应的也增加了应用研发的复杂度。
3.2.2 MVC思想极其优势
MVC思想是将一个系统分解成三个不同的层次:View(视图)、Model(模型)还有Controller(控制器),这三个层次之间轻耦合,低聚合。相互之间关联程度很低,在一起协同工作,通过这种轻耦合的框架结构可以提高系统的可维护性以及可扩展性。
起初,MVC模式是针对相同的数据需要不同显示的应用而设计的,其整体的效果参见图3.2所示。
图3.2 MVC模型
控制器根据事件的类型改变模型或视图,控制器处理事件,反之亦然。[9]这就是典型的MVC模式。举个栗子,很多视图映射到一个模型上,这种关系可以通过注册的方式来完成。也就是说,同一个模型被很多个视图注册,并被这些视图监听着。在模型变化时,所有之前注册到到这个模型上的视图就接受到了通知。然后,视图根据获取到模型的信息,更新视图。
这种逻辑过程在设计模式中是23个经典的设计模式的中之一的观察者模式的一个变种。MVC思想与观察者模式的差异在于:MVC中的对象之间是不平等的关系,被观察者是数据的载体。而观察者则仅仅是页面。而在观察者模式下,这两者可以是两个平等的对象。观察与被观察在相互之间都可以进行。
概括起来,MVC的特点参见表3-1。
表3-1 MVC的优点
MVC思想也随着时代的变化在不断发展。随着Web热潮,MVC思想在web思维下又有所不同。最大的一个变化是,我们不能主动及时通知给客户端,通知用户modal的数据发生了改变,只能在用户刷新或者视图浏览这个页面的时候才能重新更新这样的页面的内容。造成这个的主要原因是因为,Web应用是基于B/S架构,是只用用户发送请求然后服务器才能给出相对应的应答。所以无法主动将消息发送到客户端。
3.2.4 MVC在系统中的应用
经典的MVC系统中,JavaBean是Model(模型),Servlet是Controller(控制器),JSP页面是View(视图)。[10]Serlvet收集来自客户端浏览器中JSP中的requset请求,通过简单的控制逻辑将同View中发送的请求转发到相应的Modal中,由Model中的具体的编程代码来处理用户请求,再然后将结果返回给用户页面。在页面提交的表单请求,通过请求名在web.xml配置文件遍历与之相关的servlet类,再然后调用Serlvet中的Service成员方法,如果不存在这个类就在容器中Build相应的Servlet类。调用其中的Service成员函数调用响应的Model(即对应JavaBean)来处理业务逻辑。其中需要查询数据库的操作由特定JavaBean完成。这是传统的古老的应用中的MVC引用模型,现在的MVC在此基础做出了一些新的变化,演变成了四层架构。
关于MVC的一点补充,这是一种设计模式,或者说一种设计思路,一种指导性的思维。现代的观点来看,它并特定的对应到哪一种技术的那一块儿,而是泛指一种设计思想。举例来说,以纯粹的前端技术来说,不涉及服务器语言和脚本的情况下,主流上由HTML+ CSS +JavaScript构成,在这里的网页页面的呈现是由HTML来实现的,即为View,而Model是由CSS来实现的,用它来实现样式控制,而JS完成控制功能,通过JavaScript来控制行为,它是Controller;对于服务器来说,就Java Web对应的JSP +Servlet + JavaBean技术来说,这里同样有自己的MVC,而且这里的MVC更加清晰,BanJava负责数据的Model,而Servlet是Controller,而JSP是View,负责呈现内容。那更底层的数据库呢?数据库层也有对应的MVC结构,视图模式即为View,Table 模式是Modal,而事务处理则是Controller。所以,正如前面所说,MVC并不是对应特定技术的某一个块的功能特性,而是一种设计思想。
3.3 四层架构
在软件工程的发展史上,软件架构发生很大的变化,从最开始的两层结构,发展到现在比较成熟的四层架构。当然还有针对具体应用的N层架构。从二层架构具体说起:
3.3.1 二层架构
二层架构主要包括:
(1)应用程序层
(2)数据库层
在此基础上,由于人们在开发程序中,发现数据库和应用程序的耦合性太强,导致需要做很多的改变才能应对软件层次的一点小小变化,对于修改和后期维护的成本是很大的浪费。不适合与大型软件的开发和管理维护过程。于是后来演变成了三层架构。
3.3.2 三层架构
三层架构分别是:
(1)表述层
(2)业务逻辑层
(3)数据库层
在这种变化中,通过添加业务逻辑层这个中间层,解耦了应用程序的前端和后端,而且把业务逻辑放在了中间的业务逻辑层。这样能很好的满足在变化和维护的稳定性之间寻求平衡。这正好又一次佐证了计算机的那句至理名言“一切问题都可以通过增加中间层来解决”。但随着项目的不断膨胀,用户量级的不断增长,对应的数据库成了性能瓶颈,到了需要进行数据库移植的时候,三层结构虽然相对于两层结构有很大的改善,可是数据库层和业务逻辑层之间需要改变的东西还是有很多,而且也很繁琐。于是四层结构就应运而出,参见图3.3所示。
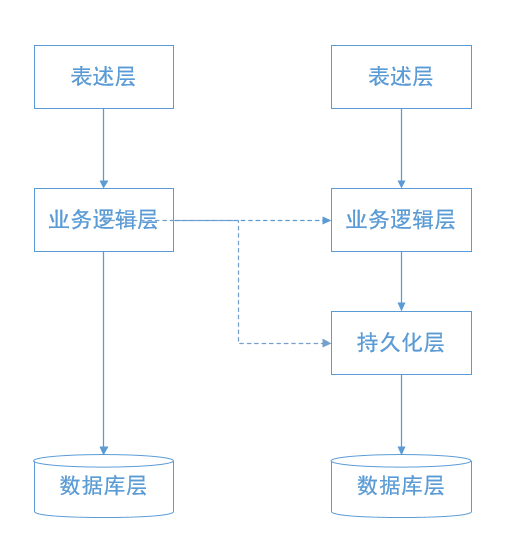
图3.3 三层结构到四层结构的演化
3.3.3 四层架构
四层架构分别是:
同样的解决思路“一切问题都可以通过增加中间层来解决”。主要是将原来的服务层分层成了业务逻辑层和持久化层,增加数据持久层之后,ORM的设计思想将数据库操作内化为程序应用的面向对象层的操作,然后通过面向对象的方法操作数据库,对于底层的数据库则完全不用管是MySQL还是Oracle,持久层的操作屏蔽了底层的数据操作,而且支持跨数据库操作。本系统采用四层体系架构。对于这种结构栈的层次架构的层与层的关系有点像TCP/IP的协议栈那样,下层为上层提供接口,下层的实现对上层是透明的。
在基于MVC的基础上的LinzhiOS系统的前端设计,主要是运用了Struts2框架,通过Struts2 对前端的JSP页面进行调度,以及其中的数据的传递和收集等工作。
3.4 配置Struts2
3.4.1 配置web.xml
将在后面具体实现LinzhiOS的所有中间层内容,系统的所有业务逻辑组件部署在Spring容器中。将系统的控制器和JSP在一起设计。因为当JSP页面发出请求之后,该请求被控制器接收到,然后业务逻辑组件由控制器来调用负责处理用户请求。其实可以说,控制器是JSP页面和业务逻辑组件之间的枢纽。
首先要在在LinzhiOS启动Struts 2,因此Struts2的核心Filter必须部署到在web.xml文件中,母的是为了通过使用该Filter把所有用户请求均拦截下来。为了实现上述功能,需要在Web.xml文件中增加如下配置片段:
|
Struts的核心Filter,在Struts2启动之后,然后再被Struts2启动。Struts2将把所有的客户的具体的各种请求都纳入系统管理之内,客户的Request将通过被FilterDispatcher的调用来调用,并通过Action的具体逻辑来处理客户的具体的用户请求。
3.4.2 整合Struts2 与Spring
整合Struts2与Spring是说,由于系统的所有业务逻辑组件都由Spring负责管理,而Action需要调用业务逻辑组件来处理来自用户的各种类别各种逻辑的用户请求,需要先注册Spring到web容器中,并且让Spring中有相应的Action的基本的bean。[6]然后才能在Struts2中调用。所以初始化Spring容器需要使用load-on-startup的Servlet或Listener,在web.xml文件中进行配置,为此我们在Web.xml文件中增加如下配置片段:
|
上面的配置文件中使用ContextLoaderListener 来初始化Spring容器。
Spring容器初始化之后, Spring容器中的Bean被Struts2的Action访问有两张方式。可以通过自动装配策略,也可以手动装配。这两种装配方式各有各的优缺点。前者简单方便缺点是不易维护,易读性很差。后者易读性好,但是配置相对繁琐一些。
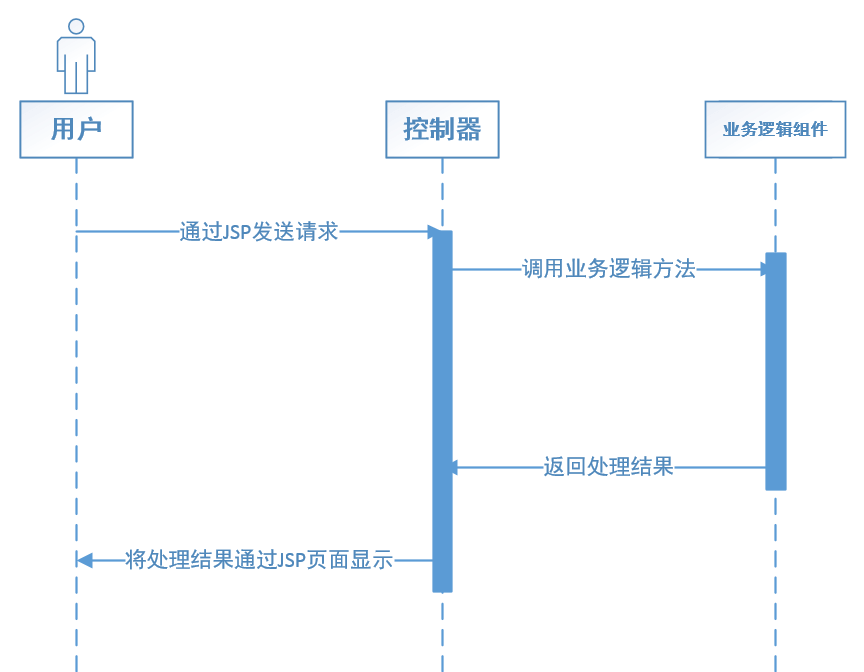
图3.4 控制器处理的顺序图
3.4.3 控制器的处理顺序
当控制器接收到用户请求之后,控制器并不会处理用户请求,只是将用户的请求参数解析出来,然后调用业务逻辑方法来处理用户请求;当请求处理完成后,控制器将处理结果通过JSP页面呈现给用户。
3.4.4 用户登录
本系统的登录页面是signin.jsp页面,当用户提交登录请求之后,用户输入的Email,password被提交到signin.action,该Action会根据请求参数决定呈现那个视图,即跳转到哪个页面,若登录成功则登录到index页面,若登录失败则回到登录页面,并且提示登录错误信息。事务操作的具体流程时序可参见图3.4。结果跳转可参见图3.5,根据不同的返回值返回到不同的页面。
3.4.5 登录验证
登录验证包括两个部分输入验证和业务逻辑(即这里的登录验证)。
输入验证也有两种方式完成:
可以由struts2 在SigninAction.java中完成,具体代码如下:
|
- 通过JavaScript完成输入验证。用JavaScript来完成输入验证的历史由来已久,上古时代的网名,那个时候,绝大多数因特网用户使用速度竟然是28.8bit/s的”猫”(调制解调器)上网,但网页的大小和复杂性却不断增加。为完成简单的表单验证而频繁地与服务器交换数据只会加重用户的负担。想象一下:用户填写完一个表单,单击提交按钮,然后等待30秒,最终服务器返回消息说有一个必填字段没有填好。[1]
这两种方式均可以,但是显然更推荐使用JavaScript来进行输入验证,考虑性能的原因,原因具体说来是,使用Struts2 方法 的验证,即便对于基本的输入验证都需要先走一遍服务器来检查用户输入的是否匹配,若不匹配再返回给用户端错误提示,而这里的这次服务器请求是多余的,而且是无效的,属于对资源的浪费。而通过JavaScript的方法实现,因为JavaScript是运行在客户端上,那么在进行输入验证的时候,如果输入不合法,则不会提交给服务器,并且直接提示客户输入有误。所以可以减少一次服务器访问,对用户友好性和性能提升很有作用。
图3.5 登录的处理结果
登录页面输入Email和Password之后,点击(或回车)提交,若输入的Email格式不正确,则对用户给出提示信息。具体的输入校验错误的情况可参见图3.6所示情况1,用户的Email输入不完整的错误提示情况参见图3.7所示,用户的密码输入不完整的情况参见图3.8所示,登录逻辑验证不完整的情况参见图3.9所示。
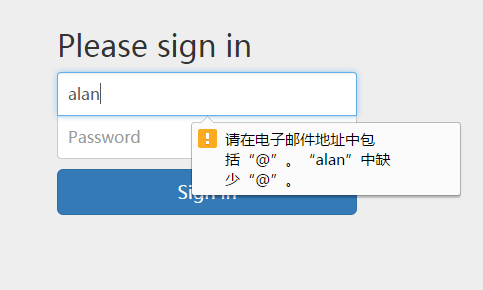
图3.6 用户的Email输入不完整的错误提示情况
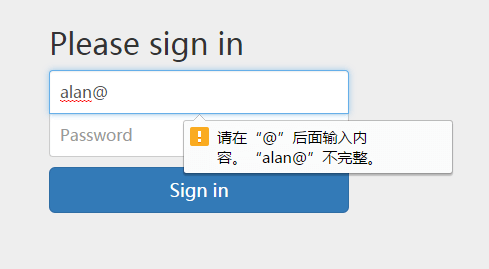
图3.7 用户的Email输入不完整的错误提示情况2
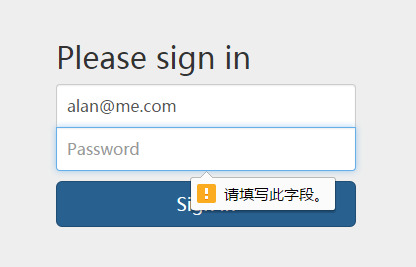
图3.8 用户的密码输入不完整的情况
当用户的输入验证通过,即Email和Password符合要求是,然后用户输入的Email和Password发送到服务器中,进行登录验证,当服务器发现用户名与密码不匹配时,在页面上的提示信息。如果登录正确,则进入用户的个人主页index。
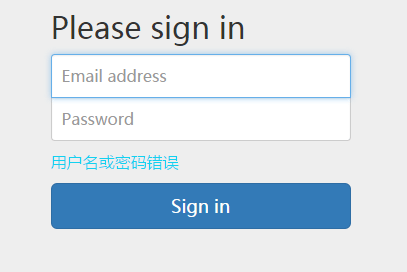
图3.9 用户的密码输入错误的情况
3.4.6 业务逻辑的登录验证
实现业务逻辑的登录验证的代码实在SigninAction的executive实现的:
|
SigninAction所实现逻辑是,将接收到的eamil和Password通过SigninService的isSignin方法进行验证,验证正确的话,返回true,否则返回false。当验证正确时,将用户的用户信息,提取出来,然后存入session中。若isSignin()返回false,则将错误信息”用户名或密码错误” 返回给用户。
Struts2 在LinzhiOS系统中的作用概略图参见图3.10所示。
上面以及提到了的登录系统,接着我继续讲解其他的模块。具体可细分为:
|
在选课模块中,又分为课表排列模块和课程选择的对class页面操作的模块。
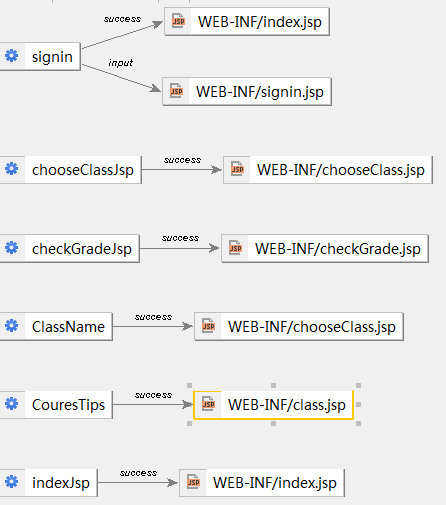
图3.10 Struts2 Action对应的不同结果
3.4.7 成绩查询模块
先说成绩查询模块。最终在用户面前(或者说,在浏览器端)呈现的页面参见图3.11所示。
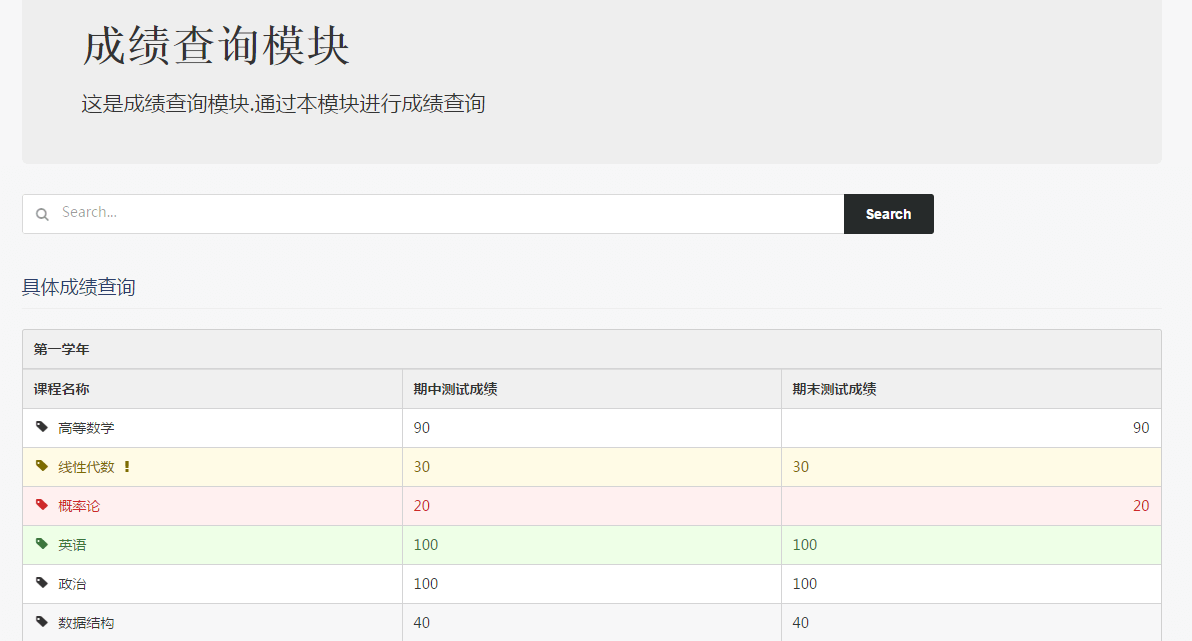
图3.11 成绩查询模块的效果图
实现过程的讲解通过纵向讲解,即从前端最表层,到内部实现过程。
在用户登录系统后,被定向到index.jsp页面。主页面的效果图参见图3.12。
在最上面的导航栏,单击成绩查询,则触发struts2 的checkGradeJsp.action。代码如下:
|
图3.12 主页效果图
具体的Action执行的操作是:为表示层JSP的查均成绩操作,于是到Service层,使用Service层提供的接口,然后然后获取到相应的学生所选修的课程,并且获得所修课程的对应的分数,并将其存入request中,至此Action执行完毕,然后Struts2在跳转到对应的checkGrade.jsp页面。在这个页面渲染时,用Struts2标签将request中的课程名和对应的成绩迭代输出到页面上。
checkGradeJspAction.Java部分核心代码如下:
|
在对应的checkGrade页面上的迭代输出的部分核心代码如下:
|
3.4.8 成绩查询模块
先说成绩查询模块。最终在用户面前(或者说,在浏览器端)呈现的页面。成绩查询模块的效果图参见图3.13。
![]/img/3.13.png)
图3.13 成绩查询模块的效果图
实现过程的讲解通过纵向讲解,即从前端最表层,到内部实现过程。
在用户登录系统后,被定向到index.jsp页面,参见图3.14。
图3.14index页面
在最上面的导航栏,单击成绩查询,则触发struts2 的checkGradeJsp.action。代码如下:
|
具体的Action执行的操作是:为表示层JSP的查均成绩操作,于是到Service层,使用Service层提供的接口,然后然后获取到相应的学生所选修的课程,并且获得所修课程的对应的分数,并将其存入request中,至此Action执行完毕,然后Struts2在跳转到对应的checkGrade.jsp页面。在这个页面渲染时,用Struts2标签将request中的课程名和对应的成绩迭代输出到页面上。
checkGradeJspAction.Java部分核心代码如下:
|
在对应的checkGrade页面上的迭代输出的部分核心代码如下:
|
3.4.9 选课模块
接下来介绍的是选课模块,单击导航栏的选课系统。选课模块的效果呈现图参见图3.15。
图3.15 选课模块的效果呈现图
其实现逻辑类似于前面讲解的成绩查询模块。但比之前的成绩查询模块要稍微复杂一些。导航栏,单击选课系统,则触发struts2 的chooseClass.action。进而有ChooseClassAction接管。之前ChooseClassAction的代码。
|
下面是getClassSchedule的核心代码。
|
首先需要使用Service为其提供的接口,来获取到对应学生的课程名称,上课时间,课程类型(是选修还是必修)等信息,并且需要他们之间的一一对应的关系。再然后,将其课程名称,上课时间,课程类型(是选修还是必修)封装到一个类中,这个类命名为ClassDetail,在将该类添加到classInfoList中,再然后,将classInfoList放到Session中,要想在JSP页面中读取到这些数据,必须将其设置到JSP的scope中,所以我将其设置到到Session中,然后在前端的JSP中,依然通过Struts2的标签库将其迭代的输出出来。到这里完成了第一阶段的呈现课程表的过程。参见图3.16,选课模块的课表。
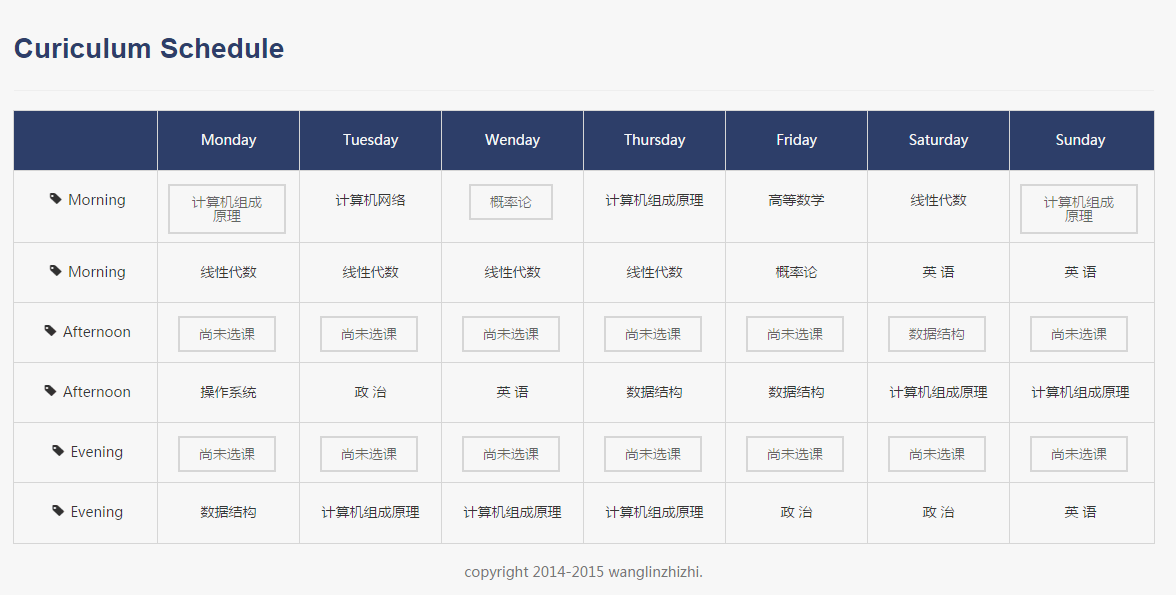
图3.16 选课模块的课表
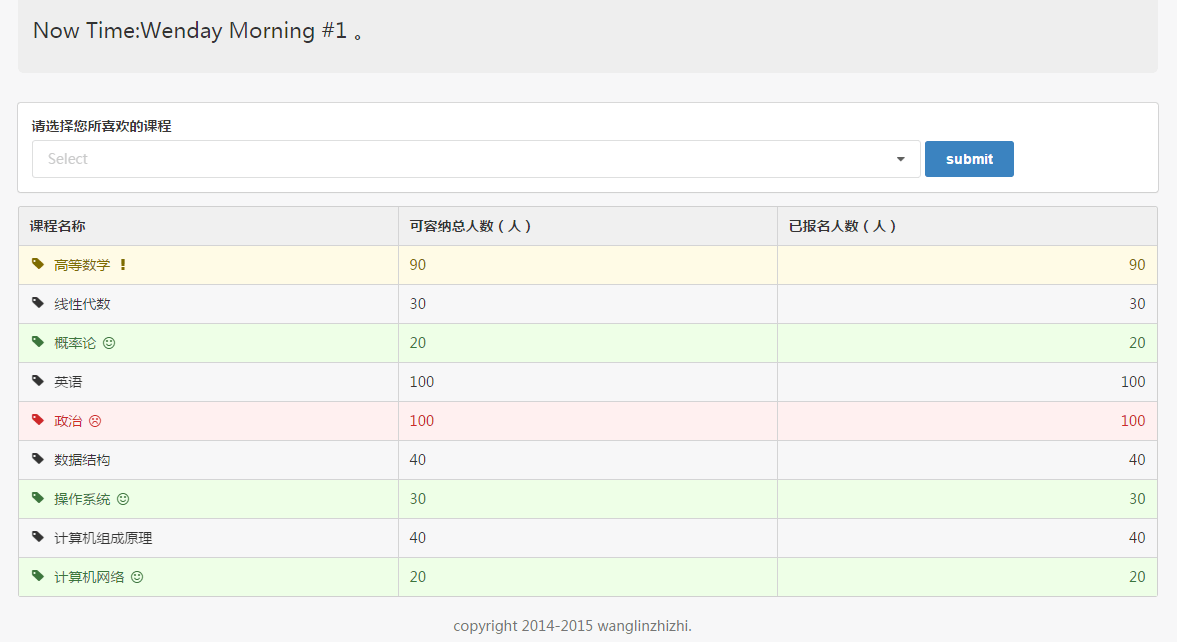
图3.17 class页面
在图3.16中我们可以看到有的格子里的显示的课程名称,但不带Button,这样的格子中的内容该课程是必修的;有些格子显示的课程名称是带button的,这些课程是选修的。而还有一些格子,是带有“尚未选课”字样,表示此时这个时间对应的那个还没有进行选课。
选课模块的另外一部分就是要实现选课逻辑。而上面的只是呈现出课表,选课逻辑的实现是通过另外的一个Action来实现的。当用户点击 “尚未选课”的button的时候(或者点击带有button的已经选课,而需要进行重新选课的时候)。单击button之后,触发CourseTips.Action,然后转入class.jsp页面。
Class.jsp页面的具体画面参见图3.17。
通过下拉框中的弹出列表的课程名进行选课操作,下拉框的逻辑具体参见图3.18,然后在下拉框所列出来的课程中进行选课,单击相应的课程名称。然后选择对应的课程,再点击提交(Submit按钮),当点击提交之后,Struts2 再次接管,进而执行ClassName. action的代码。
Struts2 的代码:
|
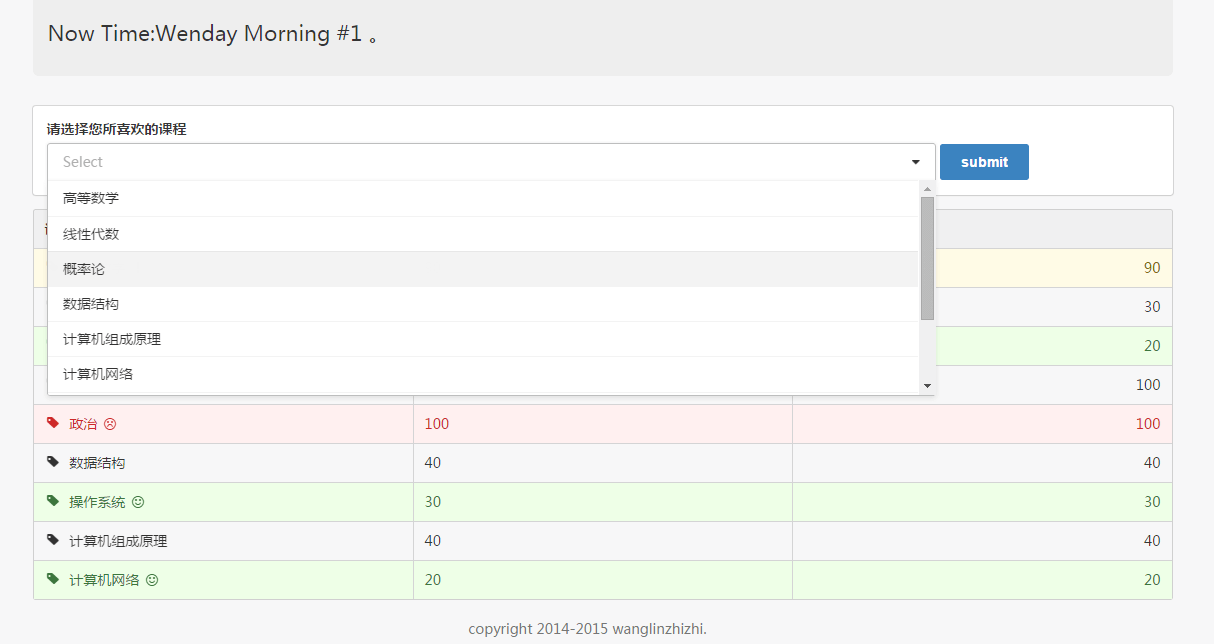
图3.18 在下拉框进行选课
className的代码的作用是将用户所选择的课程的名称,和对应的上课时间等基本信息通过Struts,通过Action,通过Action对Service的操作,将这些信息存入数据库中。与此同时,在跳转到chooseClass页面的时候,将用户刚才所选的课程,取代掉之前在那个按钮上的课程名称。
Class页面的选课模块的部分核心代码如下:
|
上述过程中,进行遍历的目的是通过先遍历一遍,检查在classInfo列表中有没有对应的classInfo.classDetails.classTimeNum == classTime,有的话,先删除,然后在在添加,或者用set方法替代掉。如果没有的话直接添加对象classDetail。
在chooseClass页面显示这些课程表,以及对应格子中的课程名称的部分核心代码如下。
|
这部分代码的目的是,填满chooseClass页面中课表的内容,课表的内容分为几种可能的情况,第一种已经选了课程的,那么将具体选择的课程放入相应的格子里(比如说,星期一的第一节课是数据结构,则把数据结构放入周一的第一节课中)。还有一类是必修课,标记classType为1的那一类课程,则直接输入到页面上来。这个过程中遍历一遍所有的课程。通过Struts2的标签负责赋值,通过标签来迅速获取到标签中的属性并且将标签中的属性迭代输出到页面上。
当从class页面选课之后跳转回到chooseClass页面的时候,需要对选课之前的格子的内容进行更新。这个过程的实现也是通过一次遍历所有课程表的课程格子来实现的。
|
除了上述的已经选了课程和必修课以及更新的课程之外,其他的格子中是没有选课的。那么将其中填满“尚未选课”字样的button。依然需要对整个所有的课程格子进行一次遍历,过滤掉已经选课了的格子和本身就有课程的格子。
|
整个过程时间复杂度为O(n)。关于选课模块的实现是本系统的核心功能之一,也是实现难度最大的部分。上述代码中涉及了几种语言的交叉编程(有JS,JQuery,JSP),目的是动态的实现课表的显示和动态实时的更新。
3.4.10 SignoutAction模块
当用户需要在使用完需要退出系统时,则需要将Session中的数据全部清楚,然后退出系统。点击更多的二级菜单,然后点击Signout,过程可参见图3.19所示。
图3.19 Signout的操作
这个过程中的退出操作也是由Struts2的Action来控制实现的。Struts2中的功能是,当执行了SignoutAction之后,将页面转到Signin.jsp页面。
SignoutAction.java的代码如下:
|
3.5 LinzhiOS的中的拦截器的设置
对于没有登录系统的用户,在系统中没有读取到他的信息,则将其请求的页面无条件跳转到登录页面,并提示其没有登录。具体的拦截器的设置如下:
|
第四章 数据库设计和实现
4.1 Hibernate简介
Hibernate是轻量级Java EE应用的持久层解决方案,Hibernate不仅管理者Java类到数据库表的映射(包括Java 数据类型到SQL数据类型的映射),还提供数据查询和获取数据的方法,可以大幅度的缩短使用JDBC处理数据持久化的时间。[4]
目前的主流的数据库依然是关系型数据库,而Java语言是面向对象的编程语言,当把二者结合一起使用时相当的麻烦,而Hibernate则减少了这个问题的困扰,它完成了对象模型和基于SQL的关系模型的映射关系。[5]
JavaEE应用能够使得面向对象分析、面向对象设计以及面向对象编程三个过程彼此和谐甚至构成一个整体是主要基于Hibernate框架。
4.2 ORM
现在流行的编程语言向Java、C# 等,它们都是面向对象的编程语言,而与之对应的当前主流的数据库软件产品像Oracle、DB2,MySQL等,依然是关系型数据库。编程语言和底层数据库之间的不协调发展,是ORM框架诞生的主要催化剂。ORM框架诞生的目标是为了解决面向对象语言和关系型数据库的不一致性。
4.2.1 对象/关系数据库映射(ORM)
ORM(即Object/Relation Mapping,对象/关系数据库映射)。ORM是一种规范,它概述了这类框架的基本特征:完成面向对象编程语言和关系型数据库的映射。由于面向对象编程在性能上稍逊关系型数据库,所以在数据库中使用关系型数据库依然有很大的性能优势。而面向对象的优势在于能够大大缩短开发时间。所以通过ORM映射之后,可以集关系型数据库和面向对象两者的优势。因此,我们可以把ORM框架当成是应用程序和数据库的桥梁。
对时下流行的编程语言而言,面向对象程序设计语言代表了目前程序设计语言的主流和趋势,具备了非常多的优势。比如:
|
但数据库的发展并未与程序设计语言同步,而且关系数据库的某些优势也是面向对象的语言无法比拟的。比如:
|
当我们采用ORM框架之后,按照上面的讲解很容易理解我们的应用程序取而代之的是以面向对象的方式来操作持久化对象(例如增删改查等),将不再直接对底层的数据库进行操作,面向对象操作向底层的SQL操作转换的具体过程将有ORM框架完成。
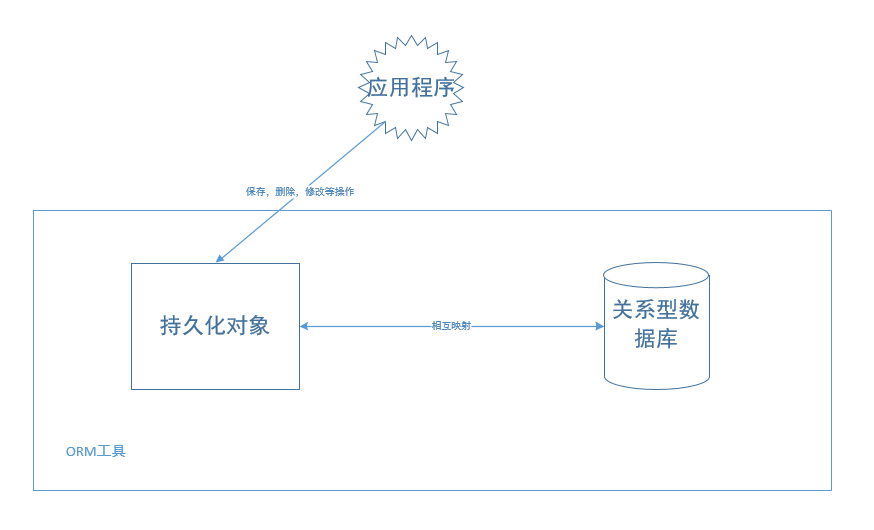
图4.1 ORM映射
参见图4.1 所示。把持久化对象的操作编译成等价的面向的关系型数据库的操作,这就是ORM框架的最主要的贡献。ORM的这种特性,使得程序员能够用面向对象的方式来操作持久化对象,进而大大提高开发速度。在底层,程序员所编写针对数据库的操作由ORM框架负责将其编译成相应的直接对数据库操作的,可以被数据库识别的SQL语句。
4.2.2 基本映射方式
数据表之间与之对应的持久化类的映射关系是有ORM框架提供的,这种映射关系,使得我们可以很直接和明显地通过持久化类对数据表进行控制。大体上来说相同的映射思路被各大ORM框架所共同遵循着。
ORM基本映射有如下这几条映射关系:
(1)数据表映射类:
持久化类映射到一个Table。当删除实例、创建实例、修改属性通过持久化类来完成时。系统自动会转换为对这个表进行CRUD操作。这种映射关系参加图4.2。
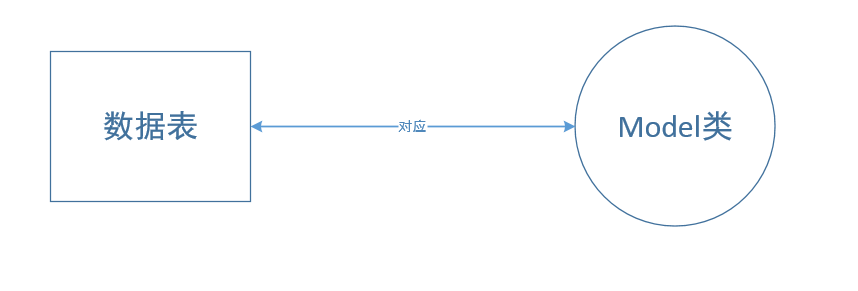
图4.2 数据表映射类
每一个被ORM管理的持久化类——本质上其实就是一个PO, 即普通的Java类——都对应一个数据表,对这个持久化类进行的操作,系统就会自动转换成对对应Table的操作。[5]
(1)数据表的行映射对象(即实例):
持久化类会生成很多的实例,每个实例就对应数据表中的一行记录。当我们在应用中修改持久化类的某个实例时,ORM工具将会转换成对对应数据表中的特定行的操作。每个持久化对象对应数据表的一行记录。参见图4.3所示。
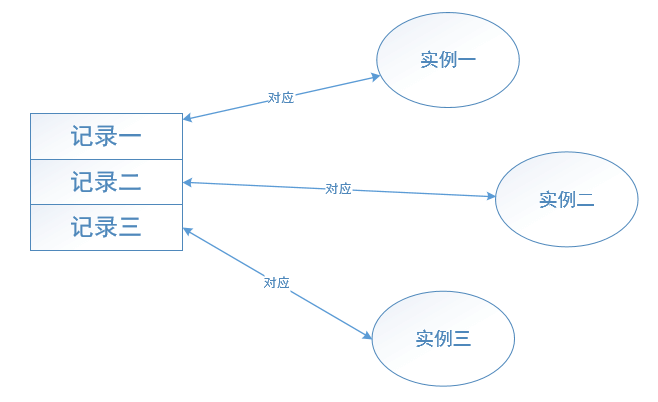
图4.3 数据表的行映射对象
(1)数据表的列(字段)映射对象的属性:
当我们在应用中修改某个持久化对象的制定属性时(持久化数据映射到数据行),ORM将会转换成对对应表中指定数据行、指定列的操作。数据表列被映射到对象属性的示意图参见图4.4。
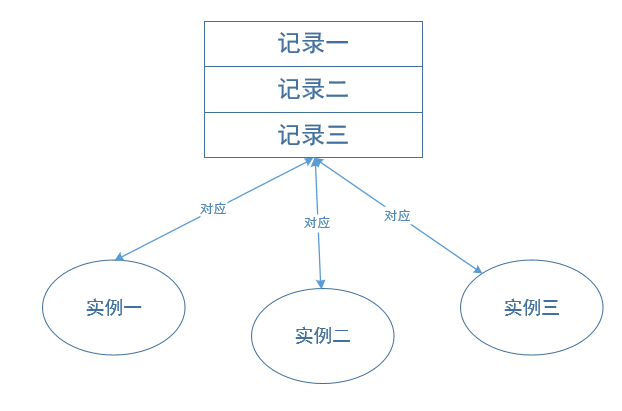
图4.4 数据表的列映射对象属性
基于这些基本的映射方式,ORM工具可完成对对象模型和关系模型之间的相互映射。显而易见的是,通过ORM框架,只要对象是被持久化之后,开发人员对数据库的操作只需要通过对持久化对象的操作,使用面向对象的方法对对象进行的操作。而不必在乎底层数据库是怎么操作的,这个过程由ORM框架负责搞定,对开发人员透明。
4.3 Hibernate 的数据库操作
ORM框架中有一个非常重要的媒介:PO(Persistent Object,持久化对象)。持久化对象的作用是完成持久化操作,也即是说,通过该对象可以对数据执行增删查改的操作,一面向对象的方式操作数据库。
应用程序无需直接进行数据库的访问,甚至无需理会底层数据库采用何种数据库——这一切对应用程序完全透明,应用程序只需创建,修改,删除持久化对象即可;与此同时,Hibernate则负责把这种操作转换为对指定数据表的操作。
Hibernate直接采用普通的POJO(普通的,传统的Java类)作为PO,这也就是Hibernate被称为低侵入式的设计的原因,Hibernate不要求持久化类继承任何父类,或者实现任何接口,这样可以不保证代码不被污染。[11]
Hiberenate采用XML映射文件使不具备持久化操作的能力一个普通的JavaBean转化成持久化类。通过映射文件就完成对数据库的操作了。
4.3.1 映射文件
Hibernate可以理解数据表和POJO类之间的一一对应,也可以理解为数据表列与属性之间的一一对应。但无法知道连接哪个数据库,以及连接数据库时所用的连接池,用户名和密码等详细信息。这些信息对于所有的持久化类是通用的,称为Hibernate配置信息,配置信息使用配置文件指定。
以执行Session.save(user) 为例说明Hibernate的执行过程.在执行Session.save(user)之前,先要获取Session对象。PO只有在Session的管理下才可可以完成数据库的访问。使用Hibernate 进行持久化操作,执行步骤如下:
(1) 开发持久化类,由POJO加映射文件组成
(2) 获取Configuration
(3) 获取SessionFactory。
(4) 获取Session,打开事务
(5) 用面向对象的方式操作数据库
(6) 关闭事务,关闭Session。
PO与Session的关联关系,PO可有如下三种状态:
(1)瞬态:如果PO实例从未与Session关联过,该PO实例处于瞬态状态。
(2)持久化:如果PO实例与Session关联过,且该实例对应到数据库记录,则该实例处于持久化状态。
(3)脱管:如果PO实例与Session关联过,但因为Session的关闭等原因,PO实例脱离了Session的管理,这种状态称为脱管状态。
这是一个比较麻烦的问题。逻辑线要这么来理顺:首先要同步到数据库中的PO操作必须在Session中合法才行。关于Session需要从Configuration对象说起,Configuration类是负责加载Hibernate配置文件的那个类。同时Configuration对象也可以生成SessionFactory,sessionFactory工厂产生Session,正常来说,一个Web应用拥有有且仅有SessionFactory对象。[12]Configuration->sessionFactory->Session->PO持久化。
使用Hibernate添加一条记录,对比Hibernate和JDBC两种操作数据库的方式,不难发现Hibernate的两个显著优点:
(1)不再需要使用编写SQL语句,而是允许采用OO(面向对象的)方式来访问数据库。
(2)JDBC访问过程中大量的checked异常被包装成Hibernate的Runtime异常,而不再需要程序必须处理所有异常。
4.3.2 Hibernate的基本配置信息
在设计持久化实体之前,在最开始需要做的工作是配置信息。配置信息主要包括:连接数据库的驱动(Drive),所连接的数据库的URL,数据库的登录角色,口令,是否在执行hibernate映射的时候显示SQL语句等。连接池的配置也是在这里配置的,连接池配主要配置的有最少连接数,最大连接数,最长超时时间等信息。配置信息放在Hibernate.cfg.xml中,具体代码如下:
|
其中的hibernate.c3p0是连接池技术,通过连接池可以在性能上起到很好的作用,连接池的原理是在容器中长期保留一定数量的开启的连接,当需要进行连接时,可以直接获取连接池中闲置的连接,而不需要重新建立一个Session,以此来提高性能。具体的内容在后面有关性能优化的地方详细说明。
值得一提的是,后面在写到Spring框架的时候我们会看到一些变化,这些变化包括现在在这里配置的Hibernate.cfg.xml在系统移植到Spring框架中的时候失效,取而代之的是将这些配置信息都写到ApplicationContext.xml中。
4.3.3 设计持久化实体
面向对象分析需要根据系统需求提取出应用中的对象,进而将这些对象抽象成类,再提取出有必要持久化保存的类,这些需要持久化保存的类就是持久化对象(PO) [14]。LinzhiOS系统没有事先设计数据库和数据表,而是完全从面向对象分析开始,数据库完全由ORM自动生成。设计的3个持久化类。
(1)Student:对应学生的姓名,Email,Password等基本信息;
(2)Course:对应课程名,课程id等信息
(3)Score:这是个管理类,用来管理相应的学生的相应的课程的选课,成绩等信息。
本系统采用贫血模式设计。故将业务逻辑分离出来,放到业务逻辑组件中去实现。
采用贫血模式的架构模型的优点是领域对象会变得非常简单,它们仅仅是简单的数据类,所以,开发起来非常便捷。而系统的所有业务逻辑都由业务逻辑层来负责实现,从而避免了将业务逻辑的变化限制在业务逻辑层内,避免扩散到两个层,从而降低了系统的开发难度。
4.3.4 创建持久化实体类
持久化对象之间的管理是以属性的方式表现出来的,持久化类之间的关联关系通常对应数据库里的主键,外键约束。
本系统中构造的类的结构图具体可参见图4.5,是Score的类图。Course的类图参见图4.6。Student的类图参见图4.7 。
图4.5 Score的类图
图4.6 Course的类图
4.3.5 映射持久化实体
以上的Stuent与课程之间是多对多映射,故Stuent中有一个Course 的Set集合,同理,Course中也有一个Student的Set集合。原因是一个学生可以选择多门课,一门课也可以被多个学生选择。所以Student与Course之间是many-to-many的关系。另外Student与Score之间,一个成绩只能对应特定的一个学生,而一个学生可以有多个成绩,所以是one-to-many的关系。同理,Course与Score之间也是,一个成绩只能对应到特定的一门课,而一门课可以有过多成绩,所以也是one-to-many 的关系。因此在Course对象和Student对象中都有Score的Set集合,而在Score对象中只是有Student对象和Course对象的单个对象的引用。
图4.7 Student的类图
以上的POJO类之间的关系很重要,是配置cfg的重要依据,在下面会用到。LinzhiOS系统中对应Student,Score,Course的映射文件如下:
|
通过上述的hbm文件,可以清晰的看到,Student与Score表的one-to-many的对应关系,Student与Course对象之间的many-to-many关系。同样从另外的两个映射文件中也可以看到这种对应关系。
这里有一个inverse=”true”的属性,是为了让many的一端来控制关联关系,而不要让one的一端来控制关联关系。
Course类的映射文件Course.hbm.xml:
|
在与Stuent表的many-to-many的映射中,有两个属性需要注意的。
cascade=”save-update”,级联操作,是指在Stuent中save或者update一个Stuent对象的信息时,对应的Course表中级联save或这update。
order-by=”idasc”。顾名思义,如果需要获取多个对象数据时,按照对象数据的id升序排列。
Socre类的映射文件Score.hbm.xml:
|
可以看到,在这三个配置文件中,都有一个id属性,与以前数据库课程中的经验不同的是,这里的id属性没有做任何有用的逻辑属性,而是纯粹的uuid码,这样做是由于Hibernate本身不提倡id属性作为逻辑属性,同时这样做也有可能到值不必要的耦合,因此不建议将id做为主键的同时还为其增加逻辑属性的做法。
4.4 实现DAO层
4.4.1 DAO层接口设计
在Hibernate持久层之上可使用DAO组件再次封装数据库操作这也是JavaEE应用的DAO模式但使用DAO模式时既体现了业务逻辑组件封装DAO组件的门面模式也可分离业务逻辑和DAO组件的功能业务逻辑组件负责业务逻辑的变化而DAO组件负责持久化的变化这正是桥接模式的应用。
引入DAO模式后,每个DAO组件包含了数据库的访问逻辑;每个DAO组件可对一个数据库表完成基本的CRUD等操作。
DAO模式的实现至少需要如下三部分:
(1)DAO工厂类
(2)DAO接口
(3)DAO接口的实现类
DAO模式是一种更符合软件工程的开发方式,使用DAO模式有如下理由参见表4-1所示。
表4-1 DAO模式的优点
对于不同的持久层技术,Spring的DAO提供了一个DAO模版,将通用的操作放在模版里完成,而对特定的操作,则通过回调接口完成。
Spring为Hibernate提供的DAO支持类是,HibernateDaoSupport。
DAO的接口定义参见图4.8所示。
将DAO分为两个大类
(1)UserDAO:这个DAO主要负责用户登录,登出,check用户是否能够正确登录,用户名密码是否匹配,新注册用户的保存,管理员对用户的删除等操作。
(2)ScoreManagerDAO:这个interface主要提供与学生,课程,选课,查成绩等功能相关的操作对应的DAO方法。
这里使用面向接口编程,对应与ScoreManagerDAO这个接口,在ScoreManagerDAOImpl中实现相应操作的具体方法。主要包括:
(1)列出所有课程:listAllClass();
(2)列出所有课程时间:listAllClassTime();
(3)列出所有课程类型:listAllClassType();
(4)更新Student,Course的信息:updateSCInfo();

图4.8 DAO层的接口定义
以下是ScoreManagerDAOImpl对于ScoreManagerDAO接口中声明的方法的实现代码。首先是ListAllScore(String Email),通过这个业务组件方法列出该学生相应的所有的课程的成绩。下面是相关函数实现的具体的相关核心代码。
|
列出所有课程时间:listAllClassTime()。通过这个业务组件方法列出该学生所有的上课时间。下面是相关函数实现的具体的相关核心代码。
|
根据用户的email,来处理用户的选课时候的选课逻辑的操作。即通过获取到用户的email,以及在选课页面获取的时间和课程类型等信息,最终确认的用户的选课信息。下面是具体的操作相关的核心代码。
|
UserDAO这个DAO主要负责用户登录,登出,check用户是否能够正确登录,用户名密码是否匹配,新注册用户的保存,管理员对用户的删除等操作。同样,在UserDAO中声明了这个DAO的接口,在UserDAOImpl中实现相关接口,主要接口参见表4-2。
表4-2 UserDAO中的接口定义
| create(Strudent student) | 新建用户,将User对象通过映射转换之后插入到关系型数据库中 |
|---|---|
| deleted (Student Student) | 删除用户,将User从数据库中删除 |
| find(String email, String password) | 通过id查找用户 |
| update(Student student) | 更新用户 |
| check(String email, String password) | 通过email,password 检查用户登录,正确返回ture,错误返回false |
以下是UserDAOImpl对于UserDAO接口中声明的方法的实现代码。首先是create(Student
student)的代码,作用是新建用户,将User对象通过映射转换之后插入到关系型数据库中。
|
对应增加用户,当然也有删除用户的操作。对应于管理员来说的。其作用是将数据库中无效的用户全部删除。下面是具体相关的核心代码。
|
以下是通过id查询相应的用户的操作,通过用户的id查询出用户对象,返回对象。下面是具体相关的核心代码:
|
Update函数的作用是在用户信息发生变化时,更新用户信息,以整个对象的形式写入到数据库中。以下是相关的部分核心代码:
|
以下的check(String email, String password)方法,作用是通过email,password
检查用户登录,正确返回ture,错误返回false。下面是具体相关的核心代码:
|
另外需要补充的一点是,在移植到Spring框架之后的代码在此基础上有所变化,以ListAllScore为对比来说明。在这里当使用了HibernateDaoSupport的情况下,可以使得代码的冗余度在很大程度上再一次减少一部分。第一次的减少是Hibernate对于关系型数据库的封装。
|
上述代码等价于下面的使用了HibernateDaoSupper的代码,可以看出这样可以进一步精简代码。
|
实质上是因为Spring中封装了hibernate操作的事务操作的代码,通过getHibernateTemplate方法,是这些需要事务处理的方法全部隐藏起来。但是需要注意的是,在使用这种方式的操作的类需要继承HibernateDaoSupper这个类。getHibernate的作用相当于上述在不使用HibernateDaoSupper的时候的try{…}catch{…}finial{…}块中的内容,从Spring的源码的文档中很容易可以找到相关内容。在Spring4以上的版本之后,关于HibernateDaoSupper有了一些变化,具体是对于事务的操作不再支持,原因是因为Hibernate3以上的版本中对于事务处理和回滚等操作已经有足够强大的支持,所以可以提倡使用Hiberenate原生的事务处理方法。
4.4.2 关于DAO层的测试
这里使用了JUnit完成,测试类的主要目的是测试,在DAO层的Impl目录下的类是否能正常的运行,是否可以正确的将数据保存到数据库中,是否能正常的从数据库中获取数据。以及事务操作是否能正常的进行,当事务操作错误时,能否正确的回滚等等基础性的操作过程。具体代码如下:
|
4.5 实现Service层
与DAO层对应,在Service层也有两个组件分别对应DAO层的UserDAO和ScoreMangerDAO。它们分别是:SigninService和ScoreMangerService。具体的作用其实主要是对ScoreManagerDAO和UserDAO的调用,调用它们的接口来完成逻辑组件的相关功能,进而为这些实现封装接口,为表现层提供所需要的服务接口,参见图4.9所示。
再往上一层,即是表现层了,在这一层,通过Action,将页面的表单当中的数据提取出来,然后Action将收集到的数据与Service层的操作进行交互,调用Service层为上层提供的接口,对表单上提交的数据进行处理,然后将结果返回给用户,并呈现在最终 的用户浏览器的页面上。
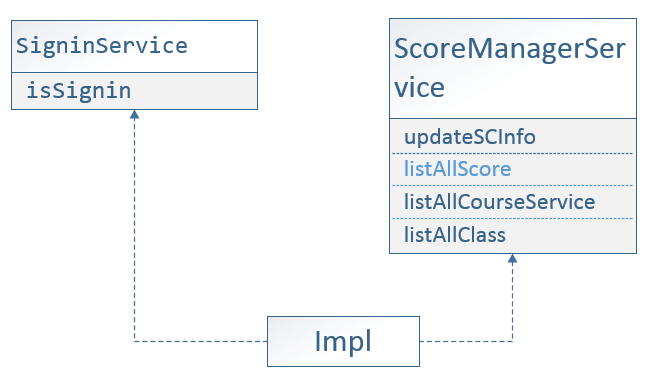
图4.9 Service层的接口设计
第五章 Spring对Struts和Hibernate的整合
5.1 Spring简介
Spring Framework是一个开源的Java/JavaEE全功能栈(full-stack)的应用程序框架,以Apache许可证形式发布,也有.NET平台上的移植版本,框架基于 Expert One-on-One JavaEE Design and Development(ISBN 0-7645-4385-7)一书中的代码,最初由 Rod Johnson 和 Juergen Hoeller等开发,pring Framework 提供了一个简易的开发方式,这种开发方式,将避免那些可能致使底层代码变得繁杂混乱的大量的属性文件和帮助类[16]。Spring的框架结构参见图5.1所示。

图5.1 Spring框架结构图
Spring 中包含的关键特性参见表5-1.
在设计应用程序Model时,MVC 模式(例如Struts)通常难于给出一个简洁明了的框架结构。Spring却具有能够让这部分工作变得简单的能力。程序开发员们可以使用Spring的 JDBC 抽象层重新设计那些复杂的框架结构。
5.2 Spring的核心机制:注入依赖
要理解注入依赖,我们先从工厂模式说起。工厂模式是依赖注入(Depends Injection)的原理,所以我们从最基础的工厂模式说起,理解了工厂模式之后,再来理解依赖注入就会容易很多。
表5-1 Spring关键特性以及具体作用

5.2.1 工厂模式
工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类(这些产品类继承自一个父类或接口)的实例。
该模式中包含的角色及其职责:
(1)工厂(Creator)角色:简单工厂模式的核心,它负责实现创建所有实例的内部逻辑。工厂类的创建产品类的方法可以被外界直接调用,创建所需的产品对象。
(2)抽象产品(Product)角色:简单工厂模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
(3)具体产品(ConcreteProduct)角色:是简单工厂模式的创建目标,所有创建的对象都是充当这个角色的某个具体类的实例。
以下是我为举例而设计的一个简单的类的类图,具体参见图5.2所示。
简单工厂模式的作用在于,当我们需要每种方法的时候,不需要在这个类中new出相应的类,然后调用这个方法,而是通过使用对应的抽象类或接口来获取到我需要的方法,因此对于上述类图中的chinese这个person类而言,当他需要使用Axe的时候,他只需要调用useAxe的方法即可,而无需管Axe类里面是如何具体的实现chop()这个方法的。我需要用斧子的时候,不需要自己去创建一把斧子,我只需要用向工厂去取,然后我使用即可。
这样做的好处是通过使用工厂类,外界可以从直接创建具体产品对象的尴尬局面摆脱出来,仅仅需要负责“消费”对象就可以了。而不必管这些对象究竟如何创建及如何组织的。明确了各自的职责和权利,有利于整个软件体系结构的优化。
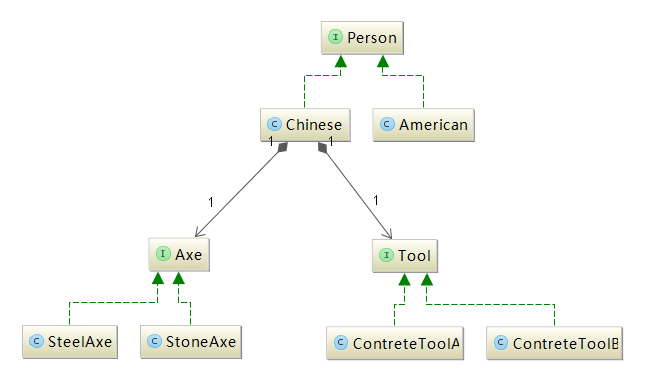
图5.2 工厂模式的类图
这是Ioc(控制反转)或者说依赖注入(DI)的核心思想:当某个Java实例(调用者)需要另一个Java实例(被调用者)时,在传统的程序设计中,通常由调用者来创建被调用者的实例。在依赖注入的末实现,创建被调用者的工作不再由调用者完成,由谁完成呢?Spring容器帮助我们完成。因此称为控制反转;创建的工作由Spring完成,然后注入调用者,因此称为依赖注入。Ioc和DI其实本质上说的是一回事儿。使用依赖注入,不仅可以为Bean注入普通的属性值,还可以注入其他的Bean的引用。通过这种依赖注入,JavaEE应用中的各种组件不需要以硬编码方式偶合在一起。而实现这种方法的本质上就是前面提到的工厂模式,很显然比上面示例的工厂模式复杂很多。
关于依赖注入的方式主要有三种,分别是
(1)设值注入setXXX()方法
(2)构造注入<constructor-arg>
(3)接口注入
本系统采用第一种方式设值注入的方式,并且无特殊原因的情况下推荐使用第一种方式。
5.3 Spring的AOP
关于AOP技术主要分为两大类:
(1)采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行。
(2)采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
Spring支持这两种AOP技术,在本论文主要讲SpringAOP,也就是通过动态代理技术的AOP。
Spring的两大关键特性,一个是上面提到的DI,依赖注入,另外一个是AOP,面向切面方法。面向切面的编程方法我们应该怎么理解呢?要理解AOP,我们首先来理解一下代理模式。
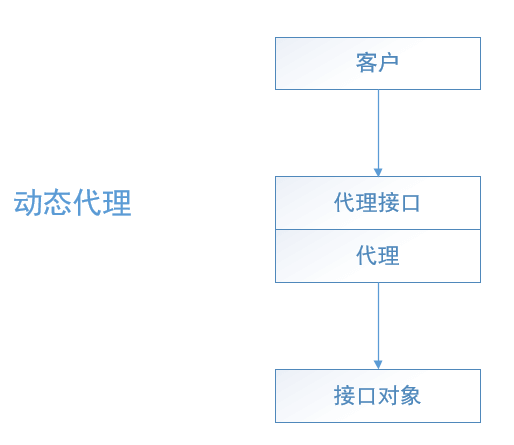
图5.3 代理模式
5.3.1 代理模式
代理模式有两种,普通的代理模式和动态代理模式。代理模式示意图参见图5.3所示。先从一般的代理模式说起。普通的代理模式参见图5.4。
使用代理模式的好处是用户在调用方法时,并不知道代理的存在,调用的方法在原来真实的对象提供的方法的基础上增加了新的其他的方法。在执行原来真实的对象提供的方法的之前或之后提供了其他的方法。从开发的角度来说,这给我们提供了极大的灵活性和方便,对其进行修改,而且不会破环远程序的完整性,因为通过Spring来操作不会产生任何耦合,会使耦合程度降到最低,也就不会对原来的代码和功能做成影响,对原来的代码的污染度很低。
代理模式的角色有:
(1)抽象角色(Subject):声明真实对象和代理对象的共同接口
(2)代理角色(Proxy):代理对象角色内部含有对真实对象的引用,从而可以操作真实对象,同时代理对象提供与真实对象相同的接口以便在任何时刻都能代替真实对象。同时,代理对象可以在执行真实对象操作时,附加其他的操作,相当于对真实对象进行封装。
(3)真实角色(realSubject):代理角色所代表的真实对象,是我们最终要引用的对象。
无论是一般的代理模式还是动态代理模式,都少不了这几种角色。
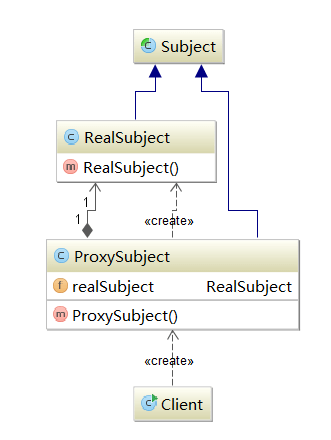
图5.4 一般的代理模式
下面通过具体的例子来说明代理模式的工作的基本原理:
首先定义一个类Client,这个类即是用户类,用户会请求一些具体的操作,会发出一些请求。用户类Client的简单代码如下:
|
用户在使用过程中,无法看到真实的对象,只能和代理打交道,通过代理来执行响应的请求,请求由代理接收,然后代理中有真实的处理该用户请求的响应事务的引用,在通过代理来调用真实对象的事务。整个过程中,client看不到真实的需要请求的对象。
然后是正真的服务类RealSubject,这个类的作用是提供给用户所需要的真正的服务。RealSubject.java的代码如下:
|
ProxySubject是代理类,这个类中含有一个真实的被代理对象的引用,即realSubject。
|
那么代理对象能做什么呢?通过代码我们能够很容易的看到:
首先,realSubject.request()能够通过使用对真实对象的引用来调用真实对象的方法完成需要真实对象完成的功能。
除此之外,代理还可以完成在代理中的不属于realSubject的方法,如在调用真实的处理方法之前的preRequest()方法,和之后的postRequest()。
这就是代理模型的作用:简单地说,它不单单完成用户请求的操作,还能额外完成其他的操作。
5.3.2 动态代理
然后我们讨论的是动态代理,动态代理比一般的代理要复杂很多。追本溯源,从java语言的反射机制说起来,通过java语言的反射机制来实现动态代理,而动态代理就是AOP的底层实现。反射机制是动态代理的基础,而动态代理是AOP的基础。
动态语言:程序运行时,允许改变程序结构或变量类型,这种语言称为动态语言。如Perl,Python,Ruby是动态语言,C++,Java, C#不是动态语言[17]。Java语言有一个突出的与动态相关的机制:Reflection。实现Java的Reflection特性主要用到的类有:Class类;Field类;Method类;Constructor类;Array类等。
通过该特性,我们可以在运行时加载,探知,使用编译期间完全未知的classes。即Java程序可以加载一个运行时才得知名称的class,获悉其完整构造(但不包括methods定义),并生成其对象实体,或对其fields设值、或唤起其methods。这种“看透class”的能力(the ability of the program toExamine itself) 被称为introspection;进一步说明,应用Java的Reflectin特性,我们可以在运行时判断任意一个对象所属的类;在运行时构造任意一个类的对象;在运行时判断任意一个类所具有的成员变量和方法;在运行时调用任意一个对象的方法[20]。这里面强调的是运行时行为。
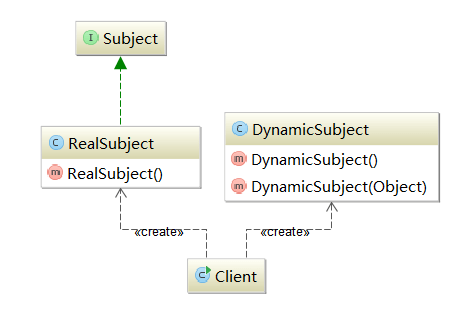
图5.5 动态代理模式
与一般的代理模式相比,如果要按照之前的方法使用代理模式,那么真实角色必须是事先已经存在的,并将其作为代理对象的内部属性。参见图5.5所示的动态地理模式。
但是实际使用时,一个真实的角色必须对应一个代理角色,如果大量使用会导致类的急剧膨胀;此外,如果事先并不知道真实的角色,该如何使用代理呢?这个问题可以通过java的动态代理类来解决。动态代理类,它是在运行时生成的class,在生成它时,你必须提供一组interface给它,然后该class就宣称它实现了这些interface。你当然可以把该class的实例当作这些interface中的任何一个来用。当然,这个Dynamic Proxy其实就是一个Proxy,它不会替你作实质性的工作,在生成它的实例时你必须提供一个handler,由它接管实际的工作。被代理的对象可以在运行时动态改变,需要控制的接口可以在运行时改变,控制的方式也可以动态改变,从而实现了非常灵活的动态代理关系。
动态代理的使用场合:
|
动态代理的步骤:
|
以下以具体的例子来讲解动态代理,与一般的代理模式类似,动态代理中也有代理类,即这里的DynamicProxy。该代理类的内部属性为Object类,实际使用时通过该类的构造函数DynamicSubject(Object obj)对其赋值;此外,在该类还实现了invoke方法,该方法中的 method.invoke(sub,args);其实就是调用被代理对象的将要被执行的方法,方法参数sub是实际的被代理对象, args为执行被代理对象相应操作所需的参数。 通过动态代理类,我们可以在调用之前或之后执行一些相关操作。
DynamicProxy的相关代码如下所示:
|
Client是需要请求操作的用户,调用者的核心的实现代码:
|
源代码中调用最后一句:subject.request()的时候会自动调用Proxy.newProxy Instance(clazz.getClassLoader(),clazz.getInterfaces(),handler);调用handler又自动转到ProxySubject中,又自调用invoke方法中的method.invoke(object,args)。在这时候完成代理的衔接。
由上述代码可以显而易见的看到动态代理的强大之处。而正是反射机制,使之成为可能。甚至可以说,是反射机制,是所有的框架称为可能。框架的建立很大程度上是依赖于反射机制的。
这是代理模式,那么代理模式与Spring的AOP怎么联系起来呢?可以这么看待,通过注入特性,Spring容器中的JavaBean,可以在执行的过程中,向其中注入本不属于该类执行过程中的其他方法,可以在执行前后加入别的与之原有功能无关的其他方法,而不影响原来的代码的执行[18]。AOP不外乎在切面处增加其他功能的执行代码,从纵向来看,不就是在原有功能的基础上完成了新的功能,横向来看就是AOP,而纵向来看就是代理模式。
那么AOP的作用是什么呢?AOP的核心思想就是“ 将应用程序的商业逻辑同对其提供辅助支持的通用服务进行分离”。
举例来说,权限控制,对于原来的Service层的java类,它们本来是无状态的java类,只负责相应的功能组件对应的功能,而对于调用这个Service组件的那个对象是否有权限执行该功能不得而知,若要想对其验证,一种方法是在每个Service层的组件中添加执行权限检查的代码,另一种方法是在执行Service层的代码之前,通过AOP方法先执行权限控制的检查,检查其是否有执行相应的Service组件的权限。第一种方案的问题是,当有很多的Service组件时,需要的权限检查代码将会需要重写很多次,代码的冗余度很大。而AOP方式则不存在这样的问题,而且更显著的一个优点是,不会对原有代码造成污染,很好的解决了代码污染的问题。
5.4 Spring框架在LinzhiOS中的应用
5.4.1部署Spring框架
在部署Spring框架时要注意除了要导入Springframework的jar文件之外,还要导入一个特殊的jar文件。struts2-spring-plugin.jar。这个Jar在Struts2 的all的压缩包下,将其放入WEB-INF的lib目录下,通过这个jar文件让Spring来接管Struts2的监听。在导入struts2-spring-plugin.jar文件时,在Struts-default.xml中,默认执行 Struts.objectFactory = spring。也就是说,将struts默认的对象工厂用spring来overridden。
同时在WEB-INF目录下的web.xml文件中添加如下代码:
|
从代码中可以很清晰地看出这段代码的作用,建立监听器,将web容器的控制权移交给Spring接管。至此,整个web容器就由Spring接管了。
org.springframework.web.context.ContextLoaderListener,它是spring的启动类,服务器一启动,listener这个类就被实例化,被运行,spring通过通过这个listener一启动,spring整个框架就运行起来了,之后spring就掌管整个系统的一切,有什么需要创建,它负责创建,有什么需要销毁,它负责销毁。
5.4.2 Spring对Strtus2 的整合
在上面我提到了Spring是一个一站式的框架(full-Stack),因此关于Struts中的对于Action的对应的JavaBean的配置,也由Spring来完成。正如Struts2 的配置文件是Struts.xml , Hibernate的配置文件是Hibernate.cfg.xml一样,Spring也有自己的配置文件,applicationContext.xml。需要将所有的struts2.xml和 Hibernate.cfg.xml的内容都写到applicationContext.xml里面去。
在Spring与Struts的合作中需要注意的一个地方, struts中的class=” ”,这里的action的name,是来自元spring中定义的action的名字(bean的id的名字);被action调用,怎么让action知道?这是由Spring帮我们完成的,我们只需在action里面声明这个action所需要的服务接口是什么。
具体代码如下:Spring中的applicationContext.xml中
关于Action的配置如下:
|
对比前面章节在没有Spring框架时的区别在于我们不需要在Struts中重新指定JavaBean,不需要重新生成JavaBean,而是由Spring负责实例化对应的Java类,我们只需在action里面声明这个action所需要的服务接口是什么。
5.4.3 Spring对Hibernate的整合
在Spring和Struts的整合中,虽然Struts的内容有所改变,但却大部分功能性的是有所保留的,包括Action对应的跳转,包括在Struts中设置的拦截器。然而,在Spring和Hibernate的整合中,Hibernate的命运就没这么好了,整个Hibernate.cfg.xml的内容均被迁移到ApplicationContext.xml中,甚至为了节省空间和不浪费表情,可以直接把Hibernate.cfg.xml删除。删除之后,那么对应底层的连接该怎么配置,已经放在哪儿呢?放在applicationContext.xml中。具体如下:
|
在这里配置基本的配置信息,取代掉Hibernate.cfg.xml的中的基本配置信息,
关于org.apache.commons.dbcp2.BasicDataSource,这是一个DBCP的数据源,DBCP是数据库连接池,使用连接池技术,就不必每次都在查询的时候需要重新建立新的连接,能在很大程度上提高性能。并且,DBCP连接池,对于应用程序来说,透明的。关于Hibernate的连接池,其实Hibernate内置了可用于学习使用的连接池C3P0,但是不适合真实工程中的高并发性。工程上一般使用的就是上述的DBCP。
destroy-method=”close”;
这段代码的意思是为了说明:既然连接池的设计是一直在连接池中有空闲的SessionFactory的话,那么什么时候关闭连接池呢?于是执行上面一段代码可以给出解决方案:当服务器关闭时,当tomcat退出时,自动销毁掉连接池进程,并且回收内存空间。
关于Hibernate的其他配置信息,在配置SessionFactory的时候在hibernateProperties中配置,配置信息如下:
|
hibernate.show_sql,hibernate.format_sql这两个设置的属性,同Hibernate.cfg.xml中设置的类似,用于在每次进行操作时,在控制器终端上显示SQL语句,在开发过程中建议开启,在完成之后,则没有必要开启着[19]。
mappingResources对应着PO的配置文件,是Hibernate对POJO进行操作的依据。因此XXXX.hbm.xml 这个文件是必须要有的,hibernate是根据这张表来生成对应的sql语句的。
为什么要配置SessionFactory呢?因为使用HibernateDaoSupport需要将Sessionfactory 注入,而sessionFactory从哪儿来呢?->sessionFactory是由spring来管理的。进而,要使用SessionFactory必须要配置数据源,所以需要配置dataSource,需要将dataSource注入SessionFactory。
5.4.4 在Spring框架中增加事务操作
Spring对于事务的实现是通过AOP是方式解决的。基本流程如下:
|
Spring的事务类 :HibernateTransactionManager。如果用Spring对某个类的某个方法或某几个方法增加事务的话。按照如下步骤:
1.声明好HibernateTransactionManager 这样的bean
2.然后利用这个bean去增强我们的需要使用事务的目标类
|
这段代码所做的事情是,将ManagerServiceImpl设置为需要事务增强的目标对象。即是在说:这就是目标对象,就是为它生成代理。
再然后,代码中的出现了一个名叫TransactionProxyFactoryBean的类,即
|
TransactionProxyFactoryBean相当于是我在前面实例中所使用的Proxy这个代理类。而且根据我们前面的例子,很显然因为它作为代理类,所以它需要有真实对象的引用,这个体现在<property name="target"ref="managerServiceTarget"/>。这行代码表明这个Proxy作为代理,它代理的是managerServiceTarget这个javaBean。
另外需要注意的是:通常事务操作配置到Service 层 这是因为有可能通过Service引用了若干个DAO,使得它所引用的不管几个DAO方法都具备了事务,在一个事务之内,要么同时成功,要么同时失败。之所以不配置DAO层,是因为有可能一个Service用到了两个DAO方法或者两个以上的DAO方法,这样的话对于Service层次来说,调用的要么将会是多个事务,或者考虑到线程安全,有可能会发生一些无法预知的错误。
5.4.5 单例模式
关于scope=”singleton”。为什么这里的scope是singleton?singleton是单例的意思。
对于spring 的配置文件的bean元素,其scope属性参见表5-2所示。
表5-2 Spring配置文件的scope属性值
| singleton | 单例模型,容器中只会生成唯一的一个对象,每次系统都调用这个类的同一个对象 |
|---|---|
| prototype | 表示每次从容器中取出bean时,都会生成一个新实例。相当于new出来一个对象。 |
| request | 该属性是基于web的,表示每次接受一个请求时,都会生成一个新实例。在这种情况下,request和prototype一样。 |
| session | 表示每个session中该对象只有一个。 |
| globalSession | 全局的session(很少用)。 |
Singleton,是GOF 23种经典的设计模式之一。在Spring中,所有未显示说明的bean都被默认设置为singleton。单例模型的特点是:1. 构造方法私有;2. getXXX() 方法是静态方法;3.类里面定义的也是静态的对象。单例的一个简单的例子的源代码如下所示:
|
对于单例模型来说,它只有一个实例,而且不能创建新的实例。
这样做得好处是什么呢?我们可以从两个角度来分析
(1)从安全的角度来说,因为只有一个实例,不会随着程序运行,产生新的类的实例,而导致占用过多的内存,或者因为流量过大,导致峰值时期产生大量的新的对象来不及回收,从而导致内存泄漏。
(2)从性能上说,对于DAO层来说,它处理的内容一般而言已经是固定的,不会再动态发生变化,是无状态的对象。那么将其设置为singleton是很合适的。
事实上,所有无状态的对象,都配置成singleton。默认的情况下,spring默认设置为scope=”singleton”与之相对应的是,对于action来说,一定要将其scope配制成prototype或是request。原因也显而易见,因为每次不同的发出请求,针对的是不同 的请求对象,不同的操作,当然应该使其重新创建出不同的Action的实例。需要引起重视的是Action和Service的配置,因为一旦配置错了,会导致系统不但性能收到影响,而且连基本的功能性也会出现问题。
5.5 基于Spring整合的LinzhiOS
至此,我们将Spring和Struts整合,再将Spring与Hibernate整合。这里省去了很多具体的配置过程,因为这些过程是繁琐而且没什么技术含量的,有一定的JavaEE编程水平的人都能做到,而没有JavaEE编程经验的人来说,讲解起来是会有大量的冗余和机械性操作,没多大意义,所以这里省去了包括环境配置,服务器搭建,Struts2的核心基础jar包的导入,Hibernate的基础jar包的导入,Spring的核心基础jar包的导入,以及相关jar包的管理工作……至此,基本上整个系统基本整合完成了。我们从配置好的ApplicationContext.xml文件中很容易地可以导出LinzhiOS的整个系统的体系结构图。参见图5.6所示。
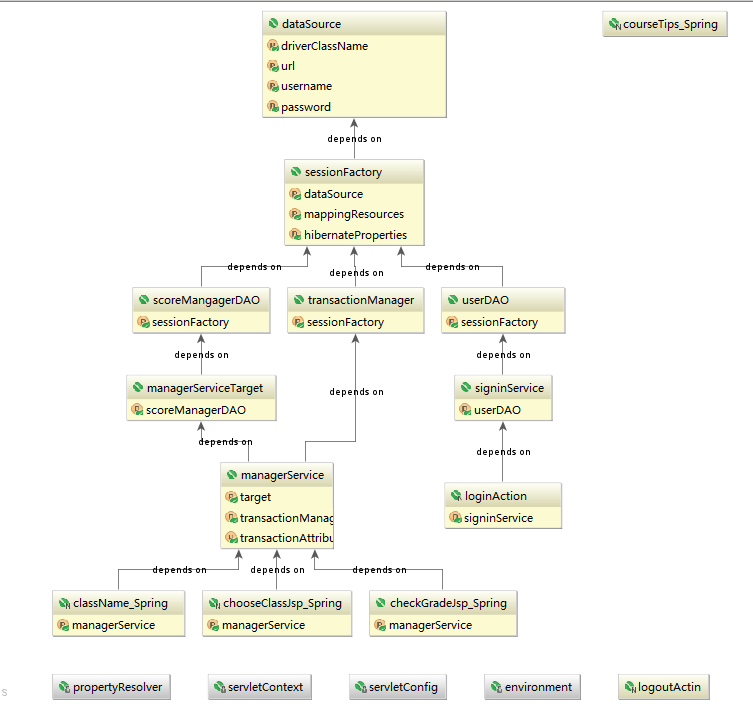
图5.6 LinzhiOS系统结构图
同时,生成LinzhiOS的整个目录结构参见图5.7
├─src│ └─linzhi│ ├─action│ ├─bean│ ├─DAO│ │ ├─HibernateUtil│ │ └─impl│ ├─interceptor│ └─service│ └─impl└─web ├─assets │ ├─brand │ ├─css │ │ └─src │ ├─flash │ ├─img │ └─js │ ├─src │ └─vendor ├─dist │ ├─css │ │ └─themes │ │ ├─basic │ │ │ └─assets │ │ │ └─fonts │ │ └─default │ │ └─assets │ │ ├─fonts │ │ └─images │ ├─fonts │ ├─img │ └─js └─WEB-INF └─lib
图5.7 LinzhiOS文件目录结构
以及相应的思维导图参见图5.8
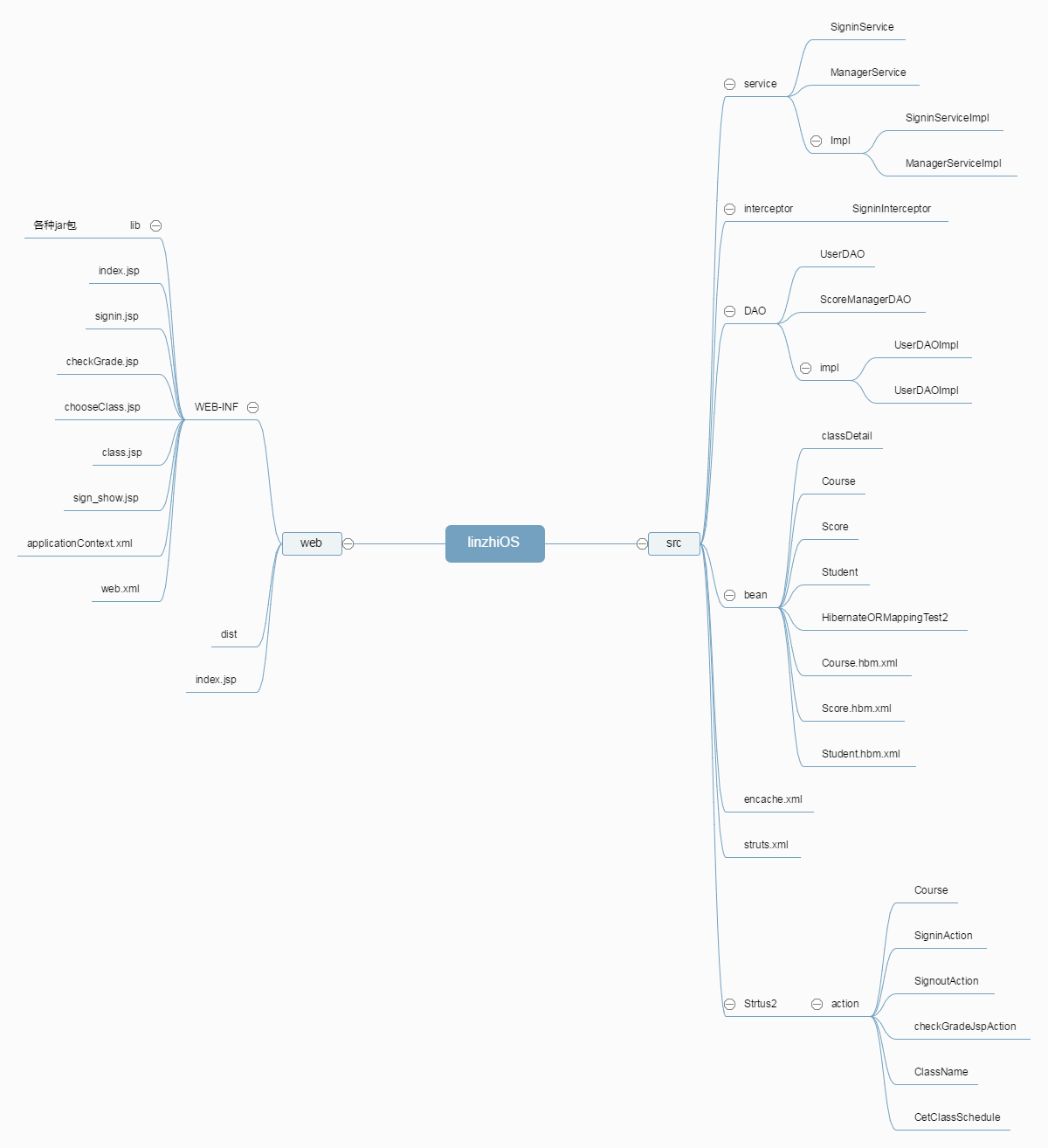
图5.8 LinzhiOS系统结构思维导图
第六章 性能优化
关于性能方面的优化主要是从以下几个角度进行的,包括数据库连接池的使用、单例模型在本系统中的运用、登录页面中输入验证的优化、chooseClass页面的数据显示的优化、Hibernate缓存设计对系统的优化。
6.1 数据库连接池
所谓数据库连接池(Connection pool),以我的理解,在容器启动的时候,数据库的连接池自动开启数个或者数十个Session,也可以理解为连接(在Hibernate中叫Session,在JDBC中叫连接更合适),然后静置。当有用户请求需要开启连接时,可以直接使用连接池里的连接,而不必开启新的连接。这样可以节省创建连接的时间和CPU开销,提高性能,当这次的查询操作执行完毕时,将连接回收到连接池,而不需要销毁掉。当下一次用户请求需要再次使用连接时,再次从连接池中取出连接来用,用完了再放回来。如果用户的访问量很大,而数据池中的连接数量不足以提供所有用户的连接请求的时候,此时再重新新建连接,并将创建好的连接用来给用户使用。总之,使用连接池,就不必每次都在查询或保存或者更新的时候建立连接了。
对于数据库的连接池,在配置文件中可以设置最小连接数量和最大连接数量。对于Hibernate内置的C3P0 的配置方式如下,在Hibernate.cfg.xml中配置C3P0代码如下:
|
连接池对于应用程序而言,是透明的。当配置好了连接池之后,之后就不用在理会了,后面在处理其他问题的时候完全可以不需要考虑连接池存在与否,因为存在与否都不会影响到程序的运行逻辑。
另外,Hibernate 内置的c3p0,可用于学习但并不适于真实工程的高并发性。工程中常用的是的DBCP,可以再Apache官网上的顶级项目Jakarta下面去找到名为DBCP的子项目。
6.2 关于Spring中单例模式的使用
单例模型,前面在介绍Spring框架的时候曾详细介绍过,使用单例模型的好处,这里再具体说明一下,很显然,只有一个实例,这样的好处之一,是节省内存,当然也就不会出现内存泄漏什么的安全问题啦,另一个明显好处,在于性能上,Java在创建Java实例的时候,需要进行内存申请;销毁实例时,需要完成垃圾回收,这些工作都会导致系统开销的增加。Spring中在对bean没有显式标注出来的情况下,默认是singleton的。Singeton作用于的Bean实例一旦创建成功,可以重复使用。因此,除非必要,否则尽量避免将Bean设置成其他的作用域。对于singleton的作用于的Bean,每次请求该Bean都将获得相同的实例。容器负责跟踪Bean实例的状态,负责维护Bean实例的声明周期行为。具体用到单例模型的地方是在对于无状态的JavaBean组件,例如Service层的某些与具体的用户角色无关的实例类,包括ScoreManagerService等,具体应用于系统的地方在:
1.managerService
|
2.scoreManagerDAO
|
3.userDAO
|
6.3 登录页面的输入验证
登录验证由两部分组成:输入验证和登录的逻辑验证。
输入验证的主要工作是:
(1)表单在点击提交的时候,是否输入了数据。若没有输入数据时,提示用户需要需输入数据,方可提交。
(2)对Email的输入框,验证输入的内容是否符合标准的Email格式,如果不符合email的标准格式时,提示用户Email格式不正确,需重新输入。
(3)对于密码框的输入校验的主要工作是,如果密码框为空时,提示用户需要输入密码,当密码框不为空时,且其他都正确时,则提交到服务器,进行进一步的登录逻辑的验证。
这种做法,比起直接通过Struts2的Action来操作的优点是,这个登录逻辑的实现中,对于只需要一次访问服务器。而对于Struts2的Action方法,则至少需要两次的服务器访问,每增加一次服务器访问,则时延就会增大。而对于直接通过前端的JavaScript的输入验证,则无需在输入验证都无法通过的情况下提交到服务器。因此而提高了性能。
6.4 chooseClass页面的数据显示
同上面的输入验证一样,通过减少一次后台的迂回,来提高系统的性能。在选课逻辑里面:当从class页面选完课程之后,传统的做法是将其保存到数据库中,然后在返回到chooseClass页面的时候,再从数据库中取出数据。这个过程中则两次连接数据库,比较浪费时间。无缓存系统的选课系统的顺序图参见图6.1所示。
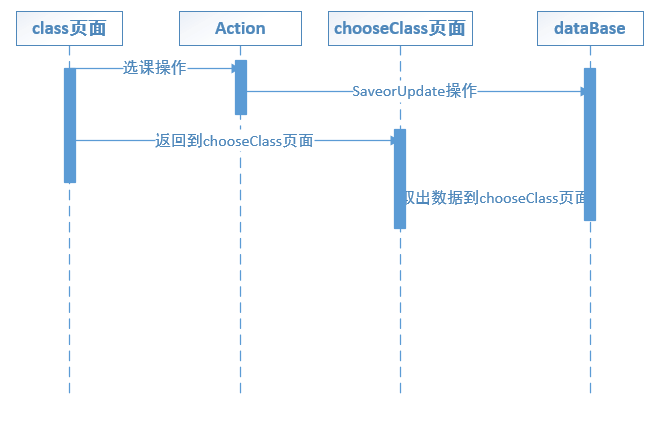
图6.1 无缓存系统的选课系统的顺序图
改进之处,在class中选课时更新的数据以及需要新增加的数据并不直接存入到数据库中,而是先将数据缓存在Session中,用一个ArrayList来维护。然后在返回到chooseClass页面时,在chooseClass页面需要用到数据时,不是到数据库中去取,而是在Session中缓存中取数据,这样真个操作就只需要一次数据库存取操作。很大程度上提高性能。具体的时序图参见图6.2所示。
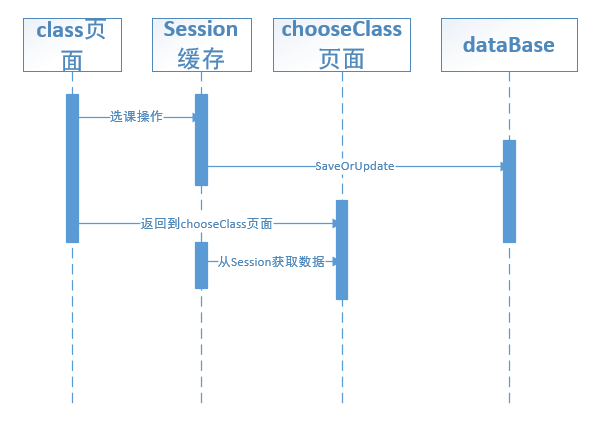
图6.2 有缓存系统的选课过程的顺序图
具体代码如下:
|
通过classInfoList.add()将新添加的课程信息添加到classInfoList 中,classInfoList是设置在Session中用于缓存课程信息的buffer区。在chooseClass页面显示的时候,之前从Session中去取得相应的数据而不需要重新去数据库中获取。
chooseClass页面的代码:
|
上述代码可能有点复杂,再解释一下,其实这是JavaScript中的一段代码,更准确的说是一段JQuery 代码,用来批量更新button中的数据(总不能对那么几十个button一个一个更新吧)。
|
这两句代码是为了将Session中的classTime和className取出来,放入到JavaScript的变量中,功能上是为了获取到classTime和className。我们知道Session是JSP中的内置对象,也就是说,在这里是JSP代码和JavaScript代码的相互嵌套使用。
6.5 Hibernate 的缓存设计
对于Hibernate和一般直接使用数据库来说,如果不使用Hibernate的二级缓存特性,其实和一般的JDBC连接数据库性能差别不大。Hibernate的二级缓存是其突出优势之一,最近的版本已经开始支持分布式的二级缓存了。二级缓存可以存放在内存中,也可以配置在硬盘上。一旦开启了二级缓存,那么对于启用了缓存的持久化类,那么SessionFactory就会缓存应用访问过的该实体类的每个对象,除非缓存的数据超出了缓存空间。
配置二级缓存,在ApplicationContext.xml中的hibernateProperties中配置:
|
然后再给对应的实体类设置缓存策略,Hibernate支持的缓存策略有:
(1)transaction:必须在在受管的环境下使用,保证可重复读的事务隔离级别,对于读写比例大,很少更新的数据通常可以采用这种方式。
(2)Read-write:使用timestamp机制维护已提交事务隔离级别,对于读写比例大,很少更新的数据通常可以采用这种方式 。
(3)Nonstict-read-write:二级缓存与数据库中的数据可能会出现不一致的情况。在使用这种策略的时候,应该设置足够短的缓存过期时间,否则就有可能从缓存中读取到脏数据。
(4)read-only:只读,当数据确定不会被改变时,我们可以使用这种缓存策略。设置缓存策略是在对应实体类所对应的映射文件(即hbm文件)中进行限制,例如:
|
还需要配置ehcache.xml文件:
|
这段代码的意思:指明缓存中最多可以放10000个对象(maxElementsInMemory
为10000);并且设置缓存是不设为永久有效的;并且设置缓存对象在300秒没有被使用就会被清除掉;在过期之前可以缓存600秒。overflowToDisk=”ture”,表示内存中缓存的记录达到maxElementInMemory之后持久耍到硬盘中,路径是diskStore,指定的位置。
6.6 小结
以上关于性能方面的优化是非常有限的,仅仅是皮毛,事实上还有很多更高级的优化是LinzhiOS所不具备的,需要更深入的学习。
第七章 安全设计
系统关于安全上的设置,从系统的文件目录的隐藏、对SQL注入的规避、使用拦截器对非合法登录用户行为进行限制这几方面进行简单地探讨。
7.1 系统的文件目录的路径隐藏
系统的目录设置(参见图6.7),其实这算是一个常规设置,就是将整个网站放在WEB-INF目录下,这样做有什么意义呢?
首先我们知道,对于系统而言,当将系统部署好之后,整个WEB-INF目录下的任何文件对外都是隐藏和不可见的,这是起到安全的基本保证,不至于让网站整个暴露在用户的关注下,换言之,如果,可以通过在地址栏就定向到特定的功能页,那么所谓的登录又有什么意义呢?我既然可以通过地址栏定位到正确的网页,那么就不必要通过登录和验证密码,直接进入系统就可以了,也就是说可以完全绕开登录系统,进入到后台。这显然是不被允许的,所以,第一层次的安全是通过将所有的Web application的内容放入到WEB-INF目录下将其隐藏起来,这样若直接在地址栏输入相应的地址,则会报404错误。那么既然web页面是被隐藏的,那么我们自己又如何到达正确的页面呢?Struts2 的Action的导航作用。
通过Struts,可以在配合Action的具体操作,引导我们到具体的页面。通过这样的 设计,系统在有益的入侵者面前或者用户的错误操作时,能够很好的面对。另外对性能和功能没有构成不必要的影响。
7.2 关于SQL注入风险的规避
SQL 注入其实是利用「歧义」的攻击手段:建造程序时候拼写的 SQL 本意,和实际攻击中生成的 SQL 不一样。
PreparedStatement等方法仅仅是降低概率,并算不上根本上防止。如果 PreparedStatement 里面写出漏洞被利用呢?再比如 rails 的 ActiveRecord 这种 ORM/DAO 方案,甚至一些敏感字符过滤方案,都是降低 SQL 注入的概率。
虽然从本质上说,对于SQL注入问题是不能完全根除的,但是这是数据库方面的一些注意事项,通过规范SQL的书写中的不规范写法,也都是会很大程度上降低SQL注入的风险的。举个简单的栗子:
|
这种SQL语句就是典型的很容易被注入的。
这句SQL语句是写在Java代码中的,而且是以字符串String的形式存在,在传参时,对于我们对于单引号中传进来的值,在运行时,用户输入之前是不知道它的内容的,那么就无法对其进行检测,是否输入非法的或者越权的操作。因为无论是什么指令被输入到了username这个变量中,只要符合String类型,只要是一个合法的String,均不会报错,因为在Java中它仅仅被视为String。所以就很容易造成SQL注入。
如果在需要输入username的地方输入‘ or ture or ’,数据库就会像收到了正确的数据库Sql指令一样继续执行。这就是典型的SQL注入。
对于这类问题的解决,在Hibernate中可以由以下的代码代替上述操作:
|
从而完成正确的功能,并且防止了SQL注入的危险。
从完全意义解除SQL注入风险的方法有吗?有,也没有。
说有的是因为:根本的手段就是参数化查询或者做词法分析。另一个关键,也就是如果支持文本式的指令,那这事儿是没有办法杜绝的,只能在外面套上一个壳,也就是词法分析。参数化查询即使这上面我所举例的方法,至于词法分析,具体来说是通过添加一个中间层,中间层执行的是对SQL语句中传入的参数进行检查,若符合正常的SQL查询逻辑,则编译通过,否则,一律视为异常。
其实现代数据库却不是只提供了SQL文本查询,参数化查询也是标准API之一,当然还有存储过程,这些高级的API都可以有效的杜绝SQL注入这种问题。在MySQL都支持存储过程的今天,还有这么多注入漏洞实在是让人费解。也就是说,我们是可以防止SQL注入的另一种方法,是使用事务和存储过程来杜绝SQL注入。
关于参数化的问题,展开说会是个很深广的话题。
各种语言的库在实现参数化查询时可以采用以下两种策略,姑且称之为
真•参数化查询:将带参数的语句及参数分别发送给DB,这种情况能100%防注入,因为对于DB来说,参数的值绝对不会作为语义要素来解析,据我所知JDBC是这种实现方式
伪•参数化查询:将拼接以后的plain SQL发给DB,只不过在拼接过程中会进行校验及转义,据我所知PHP的PDO默认是采用这种实现,不过可以通过设置开关切换为真•参数化查询,个人目前无法理解为什么要放着DB本身提供的正确实现而兜个大圈子,而且这样并不能完全避免风险,因为不能保证目前的校验及转义是否还有没考虑到的情况。
说没有的原因:首先我们知道参数化查询是DB本身提供的功能。,DB已经把能做的都做到了,一方面,DB已经提供了两种查询方式分别能正确地适用不同场景,但是DB不可能阻止程序层面错误地使用,首先,plain SQL有存在的必要,但是你无法识别程序送过来的plain SQL到底是写死的还是通过拼接来的
7.3 拦截器对未登录用户的行为的限制
这种情况是说,如果用户在没有登录的情况下,想要访问某些特定的页面怎么办呢?很显然这种情况是存在而且是有可能的,我在这里的处理方法是,设置拦截器,在执行相应的Action之前,先检查对应的操作,用户的操作行为是否是被允许的,如果不允许就不能执行,并跳转到登录页面,提醒用户请先登录。这个是实现逻辑是,用户在通过登录验证并且进入系统的同时,在容器的Session里记录下这个用户登录的信息,当用户退出时,将Session中的信息清除。当用户需要执行操作之前,先检查系统的Session中是否用相关的用户信息,如果有的话,就执行相关的操作,如果没有就不执行。于是,对于没有登录的用户来说,系统中就没有记录相应的用户信息,所以他在请求操作的时候,系统就只执行跳转到登录页面的操作,提示他需要先登录。这样就可以保证系统在用户未登录的前提下不能访问。
正如上面所说,在用户登出后,在Session中的用户信息会被清除。那么除了登出之外,还有什么时候数据会被全部清除重写呢?这个问题转化一下是说明什么时候Session中的数据会被清除,1,关闭浏览器,2,服务器关闭或重启都会将Session中的数据清除。这也就很好的保证了 以前这种情况,如果用户习惯性的关闭网页标签而没有先退出,这种情况也不会造成用户数据保留在Session中,所以,这样的操作也能保证系统在用户未登录的前提下不能访问。
还有一个问题,既然所有的有用的页面都保存在了WEB-INF目录下,那么系统在登录的时候怎么才鞥访问到的问题。这个主要是通过放在web文件夹下,WEB-INF文件夹外的index.jsp来辅助完成的。其实这个index.jsp中只有一行代码:
|
在启动服务器容器后,当需要访问这个服务器容器中这个端口的服务器程序时,用户在地址栏输入localhost:8080说明访问本LinzhiOS系统,进而系统直接将其定向到index页面,这个系统default的。而定向到这个localhost:8080/index.jsp之后,解析这个JSP页面,执行这里的forward代码,这段代码的意思是直接跳转到”/WEB-INF/signin.jsp”/,即直接跳转到登录页面。由此解决了所有信息放在了WEB-INF中,而无法访问到的问题。
从上面的放出来的文件目录中可以看到,关于JavaScript,CSS等目录都没有放到WEB-INF目录下,这些内容不需要保护吗?不需要,因为无论是JavaScript还是CSS文件,在用户请求到达后,开始响应用户请求时,这些文件都是会被下载到用户的浏览器缓存中,其实是没有必要封装到WEB-INF文件夹下的。因为即便放到了WEB-INF文件夹下,最终依然需要将其下载到浏览器缓存中,所以没有必要。
7.4 小结
其实这些所谓的安全只是皮毛,是入门级的安全防护。随着安全级别的升高,对应的安全防护的技术要求也会越来越高。我所听说过的入侵方法,例如利用第三方伪装监听信道侵入系统,利用渗透技术侵入系统,利用内存溢出的漏洞侵入,利用撞库侵入系统,甚至框架本身缺陷侵入系统(比如前一年爆出的Struts2.1 漏洞)等,以及很多我所不知道的甚至没有听说过的侵入方法。这些都是我现在无能为力的解决的。系统安全是一门精深学问。
总 结
本论文基于对Struts2,Hibernate,Spring框架的学习,进而运用这些技术完成了设计实现了学生信息管理系统(LinzhiOS):运用Struts2对LinzhiOS系统在实现前端控制,通过使用Hibernate将数据库的操作简化为使用面向对象的方式来操作,通过Spring框架对LinzhiOS学生信息管理系统用Hibernate和Struts2整合,完成整个系统的基础功能的搭建。基本完成了本系统的基础性的功能。然后在论文的后两章节从系统安全性和系统优化等角度对系统进行了进一步的完善和优化。到了这里整个系统的功能就基本完成了。
|
有些是在开始之前能够预见到的,比如对Strtus2,Hiberante,Spring等技术因为熟悉度的原因而遇到的一些本可避免的问题,对于Struts2,Hibernate,Spring框架理解不透彻而导致的问题,归根到底,书读少了。
另外,其实有更多的问题是,是系统开发过程中遇到的问题,在每次开发之前心中或多或少都会有设计思路,按照已有的设计思路来写代码,但是写到一半甚至写到最后才发现,这种方案走不通,于是需要全部重新推倒重新设计,重新写代码,比如像刚开始,在对Hibernate中进行查询时,总会联想到用关系型数据库的SQL语句来写代码,然后事实上HQL虽然和SQL有相似,但是还是有很大的差别的,这种情况下只能吸取教训,重新思考……
以上的问题,或多或少都能通过各种资料和网上查询资料获得一定程度(虽然不可能是完全的)的启发。还有一类问题,则只能靠自己的来解决。有这么一类问题,是只有我这个系统的才特有的问题,这样的问题,只能通过自己来解决。比如说,比较典型的是关于选课模块中课表的实现方法,这里之所以想使用这种方式,而不是传统的类似方正的学生信息管理系统的实现,原因是这样的系统实现对于用户友好度更好,而且用户能够更清晰的知道怎么使用,以及,能够更直接的运用该系统。把简洁留给用户,把复杂留给自己。这么做可以使系统简化,但是却增加了开发难度,对于每个课程放在格子的那一个地方这个设计过程就比较麻烦。一开始我设计了几个复杂的数据模型试图解决这个问题,比如设计横纵坐标的方式,比如设计时间参数的方式等等,但是效果都不理想,经过多次尝试,最终通过一种简介的数学模型解决了这一问题,特别感受到数学之美的奇妙。让我感受颇深的是吴军博士在《数学之美》中的一段话:“数学常常给人一种深奥和复杂的感觉,但是它的本质常常是很简单而直接的。英国哲学家培根在论美德时讲‘美德如同华贵的宝石,在朴素的衬托下最显华丽。’数学 的妙处也恰恰在于一个好的方法,常常是最简单明了的方法。”在处理这个选课系统的课表问题时,也印证了吴军在《数学之美》的书中所讲的简单即是美的观点。一个优雅的设计在一定程度上一定是最简洁而且清晰的,大到搜索引擎的设计,小到一个选课系统的选课模块的排列等方面的问题。
另一个感悟是来自于性能优化部分时的感悟:业界流传很广的一句话:“一切问题都可以通过使用中间层来解决。” 对于系统看似是一个整体的过程,其实仔细分析,一定能将其进行更细腻的分层。就像流水线操作一样,一个完整过程总可以将其划分为流水操作。分层的目的,则是尽可能的提高资源的利用率以及性能。例如,在做选课系统的过程中,就是通过对显示课表数据的过程从一个事务的数据库查询将其分层为在前端进行数据缓存,在后台才执行选课过程,从而减少了一次IO时间,进而提高了系统的性能。
通过处理完这些问题,到了这一步系统的设计实现就算完了吗?还没有,还有需要做的事情还有很多:一些在现有系统之上的一些bugs,制作了几个简单的测试,并未全面的对系统进行测试,所以可能定还有很多bugs是需要慢慢排查的,此其一。另外功能的扩展,对于其他角色的功能上的扩展,比如说教师模块,管理员模块等。第三,性能优化和安全防护永远是永无止境的。以及,离开了用户量级来说系统都是不负责任的行为,随着系统承载的用户量级的提升,系统的稳定性和承载力将是一个很有考验的工作,这些都是现阶段尚未完成的工作。对于整个系统,可以从深度和广度两个角度来划分,广度上探讨的是功能的横向扩充,功能模块的增加,深度上探讨的是现阶段的系统的基础上,在某些其他方面需要完善的内容,现阶段尚未完成的工作具体参见表8-1所示。
需要改进完善的地方
广度上 :
现在的系统,仅仅是完成了部分学生操作的子模块,还有管理员模块,还有教师模块都还没有写完。这些模块的完善工作相对来说在底层的扩展接口的前提下相对比较容易继续搭建。
|
深度上 : 性能优化是件永无止境的事情,尽一切可能的从体系架构上和设计上压榨服务器性能。
|
–end–
by wanglinzhizhi